강좌 동영상 보기(YouTube) : Unite 2016: 모바일 애플리케이션 최적화
1. 프로파일링
성능을 개선하기 위한 모든 최적화 시도는 발견 프로세스로 시작해야 한다는 사실을 기억하십시오.
애플리케이션을 프로파일링하여 문제점을 파악하는 것이 첫 단계여야 하며, 그 이후 프로젝트의 기술적 사항과 에셋 아키텍처를 프로파일링 결과와 비교 분석해야 합니다.
이 장에서는 네이티브 코드 프로파일링 트레이스에 존재하는 메서드 이름을 다루는데, 이는 Unity 5.3 버전을 기반으로 합니다.
메서드 이름은 향후 유니티가 업데이트 되면 바뀔 수 있습니다.
1.1 툴
유니티 개발자를 위해 다양한 프로파일링 툴이 준비되어 있습니다.
유니티는 CPU 프로파일러, 메모리 프로파일러 그리고 새로 추가된 5.3 메모리 분석기 등과 같은 빌트인 툴을 갖추고 있습니다.
하지만, 최선의 결과를 얻으려면 다음과 같이 플랫폼 별로 특화 툴을 사용하는 편이 좋습니다.
① Intel CPU/GPU를 사용하는 플랫폼
- VTune : https://software.intel.com/content/www/us/en/develop/tools/vtune-profiler.html
- Intel GPA : https://software.intel.com/content/www/us/en/develop/tools/graphics-performance-analyzers.html
② Android
- Snapdragon Profiler : https://developer.qualcomm.com/software/snapdragon-profiler
③ iOS
- XCode Frame Debugger : https://developer.apple.com/documentation/metal/frame_capture_debugging_tools
④ PS4 : Razor, VR Trace
⑤ Xbox : Pix(Performance Investigator for Xbox) - DirectX 최적화, 디버깅이 가능한 툴.
이 툴은 일반적으로 프로젝트의 C++ 버전을 만들기 위해 IL2CPP를 활용할 수 있는 플랫폼에서 가장 유용합니다.
네이티브 코드 버전은 Mono에서 실행할 때는 쓸 수 없는 투명한 콜스택과 고해상도 메서드 타이밍을 제공합니다.
유니티는 iOS 게임을 프로파일링하는 툴에 대한 기본 가이드를 작성했습니다. Profiling with Instruments를 참조하십시오.
1.2 시작 트레이스 분석
이 두 가지 키 메서드도 반드시 이것을 사용해야만 트레이스할 수 있는 것은 아니기 때문입니다.
이는 프로젝트의 설정, 에셋, 코드가 시작 시간에 영향을 주로 주는 부분이기 때문입니다.
플랫폼마다 시작 시간이 상이하게 나타난다는 점을 상기하십시오.
대부분의 플랫폼에서는 정적 스플래시 화면으로 사용자에게 표시됩니다.
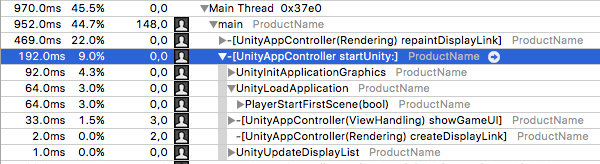
위의 스크린샷은 iOS 디바이스에서 실행되는 샘플 프로젝트의 Instruments 트레이스입니다.
플랫폼 종속적인 startUnity 메서드에 있는 UnityInitApplicationGraphics와 UnityLoadApplication 메서드에 주목하십시오.
UnityInitApplicationGraphics는 그래픽스 디바이스 설정이나 유니티 내부 시스템 초기화와 같은 다양한 내부 작업을 실행합니다.
이와 더불어 리소스 시스템 역시 초기화합니다.
이들 작업을 진행하려면, 리소스 시스템에 있는 모든 파일의 색인을 우선 로드해야 합니다.
“Resources” 이름을 가지는 모든 폴더에 포함된 에셋 파일이 리소스 시스템 데이터에 포함됩니다.
이는 프로젝트의 “Assets” 폴더에 위치하는 “Resources” 폴더와 그 자식 폴더에만 적용됩니다.
따라서 리소스 시스템을 초기화하는 데 걸리는 시간은, 거의 정비례하게, “Resources” 폴더에 있는 파일의 개수에 따라 증가합니다.
UnityLoadApplication은 프로젝트의 첫 씬을 로드하고 초기화하는 메서드를 포함합니다.
이는 셰이더 컴파일링, 텍스처 업로드, 게임 오브젝트 인스턴스화와 같이 첫 씬을 표시하는 데 필요한 모든 데이터를 역직렬화하고 인스턴스화하는 작업을 진행합니다.
이와 더불어, 첫 씬의 모든 MonoBehaviour는 이 시점에서 Awake 콜백을 실행합니다.
이 과정은, 만약 프로젝트에서 첫 씬의 Awake 콜백에 오래 걸리는 코드가 있는 경우 해당 코드로 인하여 프로젝트 전체의 초기 시작 시간을 지연시킬 수 있다는 점을 보여줍니다.
이를 해결하기 위해서는 느린 해당 코드를 제거하거나 애플리케이션의 다른 부분에서 실행되도록 해야 합니다.
1.3 런타임 트레이스 분석
초기 시작 시간 이후 캡처된 프로파일링 트레이스의 경우, 주로 고려할 곳은 PlayerLoop 메서드입니다.
이것은 유니티의 메인 루프이며 매 프레임당 한번씩 실행하는 코드입니다.
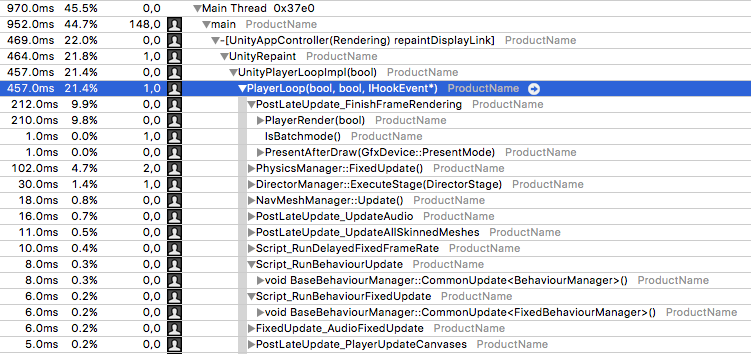
위의 스크린샷은 Unity 5.4 샘플 프로젝트의 프로파일링을 실행한 것이며, PlayerLoop의 가장 주목할 만한 몇 개의 메서드를 보여줍니다.
PlayerLoop의 메서드 이름은 유니티 버전에 따라 다를 수 있다는 점을 기억하십시오.
PlayerRender는 유니티의 렌더링 시스템을 실행하는 메서드입니다.
이는 오브젝트 컬링, 동적 배치 계산, GPU에 드로우 명령 전달 등과 같은 작업을 진행합니다.
모든 이미지 이펙트나 렌더링 기반 스크립트 콜백(OnWillRenderObject 등) 역시 이 곳에서 실행됩니다.
일반적으로, 메서드는 프로젝트가 상호작용을 하는 동안 CPU 사용 시간을 가장 많이 소모합니다.
BaseBehaviourManager는 3개의 CommonUpdate 템플릿 버전을 호출합니다.
이는 현재 씬에서 액티브 게임 오브젝트에 포함된 MonoBehaviours의 특정 콜백을 호출합니다.
- CommonUpdate<UpdateManager>는 Update 콜백을 호출합니다.
- CommonUpdate<LateUpdateManager>는 LateUpdate 콜백을 호출합니다.
- CommonUpdate<FixedUpdateManager>는 물리 시스템을 활성화한 경우 FixedUpdate 콜백을 호출합니다.
일반적으로 BaseBehaviourManager::CommonUpdate<UpdateManager> 메서드는 검사해야 할 가장 흥미로운 메서드입니다.
왜냐하면, 이 메서드는 유니티 프로젝트에서 작동하는 대부분의 스크립트 코드에 대한 진입 지점이기 때문입니다.
다음과 같이 흥미있는 여러 다른 메서드도 있습니다.
UI::CanvasManager는 프로젝트가 Unity UI를 사용하는 경우 다양한 콜백을 호출합니다.
이는 Unity UI의 배치 계산 및 레이아웃 업데이트를 포함하며, 이 두 개의 작업은 유니티 프로파일러에 매우 많은CanvasManager가 나타나도록 합니다.
DelayedCallManager::Update는 코루틴을 실행합니다.
이 메서드는 “코루틴” 장에 더 자세하게 설명되어 있습니다.
PhysicsManager::FixedUpdate는 PhysX 물리 시스템을 실행합니다.
이는 우선 PhysX의 내부 코드를 실행하며, 리지드바디와 콜라이더 같은 현재 씬의 물리 오브젝트 수에 영향을 받습니다.
하지만, 물리 기반 콜백 특히 OnTriggerStay와 OnCollisionStay 역시 여기에 나타납니다.
만일 프로젝트가 2D 물리 시스템을 사용하는 경우, 이는 Physics2DManager::FixedUpdate 에서 유사한 호출 집합으로 나타납니다.
1.4 스크립트 메서드 분석
만일 스크립트가 IL2CPP로 교차 컴파일된 플랫폼에서 호출되는 경우 ScriptingInvocation 오브젝트를 포함하는 트레이스 줄을 찾아보십시오.
여기가 스크립트 코드를 실행하기 위해서 유니티의 내부 네이티브 코드가 스크립트 런타임으로 전환하는 지점입니다.
기술적으로는, IL2CPP를 통하여 실행된 경우 C#/JS 스크립트 코드는 네이티브 코드가 됩니다.
하지만, 교차 컴파일된 코드는 우선적으로 메서드를 IL2CPP 런타임 프레임워크를 통하여 실행하며, 이는 손으로 작성한 C++코드와는 유사하지 않습니다.
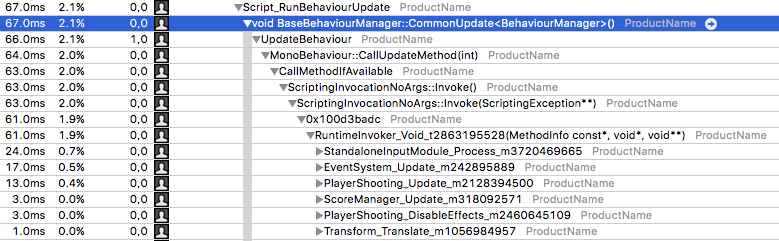
위의 스크린샷은 Unity 5.4 에서 실행되는 샘플 프로젝트에서 가져온 것 입니다.
RuntimeInvoker_Void 줄 아래에 위치한 모든 메서드는 프레임당 한 번 실행되는 교차 컴파일된 C# 스크립트 부분입니다.
트레이스 라인은 비교적 이해하기 쉽습니다.
각각의 메서드는 오리지널 클래스의 이름과 오리지널 메서드의 이름 방식으로 명명되었습니다.
이 예제에서는, EventSystem.Update, PlayerShooting.Update와 같은 다수의 Update 메서드를 볼 수 있습니다.
이는 대부분의 MonoBehaviour에 있는 기본 Unity Update 콜백입니다.
이러한 메서드를 확장하면 내부에서 어떤 메서드가 CPU 시간을 소모하는지 파악할 수 있습니다.
이는 프로젝트의 다른 스크립트 메서드, Unity API와 C# 라이브러리 코드를 포함합니다.
위의 트레이스는 터치 이벤트가 UI 요소 위에 올라왔는지 또는 활성화하는지를 감지하기 위해 StandaloneInputModule.Process 메서드로 프레임당 한 번씩 전체 UI를 레이캐스팅 하고 있는 것을 보여줍니다.
주로 CPU 시간을 차지하는 것은 UI 요소를 전부 반복하는 작업과, 마우스의 포지션이 경계 사각형에 있는지 테스트하는 작업입니다.
1.5 에셋(Asset) 로드
에셋 로드 역시 CPU 트레이스에서 파악할 수 있습니다.
에셋 로드를 나타내는 주된 메서드는 SerializedFile::ReadObject입니다.
이 메서드는 바이너리 데이터 스트림을 유니티의 직렬화 시스템에 연결합니다.
이 직렬화 시스템은 Transfer 라는 메서드를 통해 작동합니다.
Transfer 메서드는 텍스처, MonoBehaviour, 파티클 시스템과 같은 모든 에셋 종류에 존재합니다.

위의 스크린샷에서는 한 개의 씬을 로드하고 있습니다.
이는 유니티가 씬의 모든 에셋을 읽고 비직렬화하는 과정을 포함하며, 이들 작업은 SerializedFile::ReadObject 아래 다양한 Transfer 메서드가 호출하고 있는 것을 볼 수 있습니다.
일반적으로, 만일 런타임 도중 성능이 저하되고, 성능 트레이스 결과 SerializedFile::ReadObject가 상당한 시간을 차지하고 있는 것으로 나타난다면 에셋 로드로 인하여 프레임 속도가 저하됩니다.
대부분의 경우 SerializedFile::ReadObject 메서드는 동기화된 에셋 로드가 SceneManager, Resources, 또는 AssetBundle API를 통해 요청되는 경우에만 메인 스레드에 존재합니다.
이런 종류의 성능 저하는 일반적인 방법을 통해 해결할 수 있습니다.
에셋 로딩을 비동기화 시키거나 (이는 무거운 ReadObject 호출을 워커 스레드에 넘기게 됩니다), 특정 무거운 에셋을 미리 로드할 수도 있습니다.
Transfer 호출은 오브젝트를 복사할 경우에도 나타납니다
(이는 트레이스에서 CloneObject 메서드로 나타납니다).
만약 Transfer 호출이 CloneObject 호출 아래에서 나타나는 경우, 에셋은 저장소에서 로드되지 않습니다.
대신, 이전 오브젝트의 데이터가 새로운 오브젝트로 전송됩니다.
이를 위해서, 유니티는 이전 오브젝트를 직렬화하고, 결과 데이터를 비직렬화하여 새로운 오브젝트로 만듭니다.
2. 메모리
메모리 소비는 성능을 나타내는 중요한 요소이며, 이는 특히 저사양 모바일 디바이스와 같이 제한된 메모리 자원을 가진 플랫폼에서 중요합니다.
2.1 메모리 소비 프로파일링
유니티에서 메모리 문제를 진단하는 가장 좋은 방법은 유니티의 Bitbucket에서 다운로드할 수 있는 오픈 소스 메모리 시각화 툴을 사용하는 것입니다.
[설치 방법]
① 다운로드 : https://bitbucket.org/Unity-Technologies/memoryprofiler/src/default/
② 참고 동영상 : https://www.youtube.com/watch?v=7B6xRYMzst8
③ 설치 : 프로젝트 Editor폴더를 프로젝트로 복사하면 됩니다.
파일을 복사하면, ZoomArea.cs(412,18):, ZoomArea.cs(428,18):, ZoomArea.cs(440,18):, ZoomArea.cs(456,18): 에서
error CS0619: 'EventType.scrollWheel' is obsolete: 'Use ScrollWheel instead (UnityUpgradable) -> ScrollWheel'라는 에러가 발생할 수 있습니다.
[해결 방법]
- EventType.mouseDown: → EventType.MouseDown:
- EventType.mouseUp: → EventType.MouseUp:
- EventType.mouseDrag: → EventType.MouseDrag:
- EventType.scrollWheel: → EventType.ScrollWheel: 으로 변환.
이 툴을 사용하려면 IL2CPP 스크립트로 작성된 프로젝트를 빌드한 이후, 이를 적절한 장치에 설치합니다.
[사용 방법]
① 유니티의 에디터 내장 CPU 프로파일러를 연결한 후, 메모리 프로파일러 창을 열고,
② 메뉴 > Window > MemoryProfiler
③ MemoryProfilerWindow 창이 뜨면, Take Snapshot 클릭.
④ 기다림...(트레이스 분석 과정은 약 10분에서 30분 정도 소요될 수 있음.)
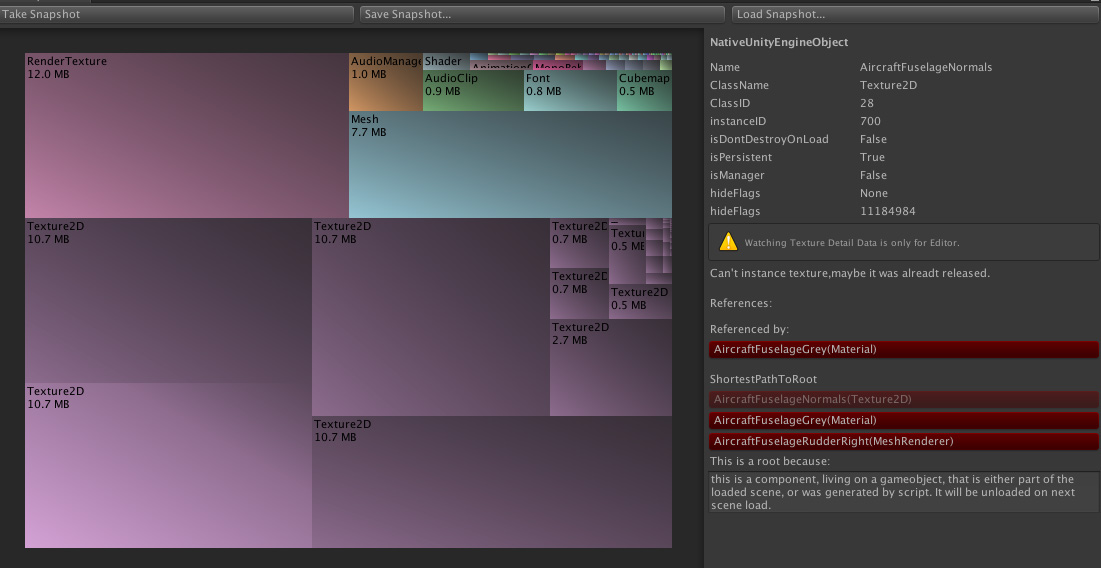
위의 스크린샷은 iOS 디바이스에서 작동하는 스탠다드 에셋 씬이며, 메모리 사용의 3/4 이상이 비행기의 동체에 관련된 네 개의 아주 거대한 텍스처에 할당된 것을 볼 수 있습니다.
이 시각화 그래프는 확대할 수 있습니다.
애플레케이션의 각 상자를 클릭하면 그에 대한 자세한 정보를 확인할 수 있습니다.
2.1.1 중복된 텍스처 식별
메모리에서 에셋이 중복되는 것은 자주 일어나는 메모리 문제 중 하나입니다.
보통 텍스처가 프로젝트에서 가장 메모리를 많이 차지하는 에셋이므로, 중복되는 것은 유니티 프로젝트에서 주로 발생하는 가장 일반적인 메모리 문제 중의 하나입니다.
중복된 에셋을 파악하려면, 동일한 에셋에서 로드된 동일한 종류와 크기를 가지는 두 개의 오브젝트를 찾아보면 됩니다.
새로운 메모리 프로파일러의 세부 정보 창에서 동일한 것으로 보이는 오브젝트의 Name 과 InstanceID 필드를 확인해 보십시오.
Name 필드는 오브젝트가 로드된 에셋 파일의 이름에 따릅니다.
일반적으로, 필드의 값은 파일의 경로와 확장자가 빠진 파일 이름입니다.
InstanceID 필드는 유니티 런타임이 할당한 내부 식별 번호이며, 이 숫자는 유니티 게임의 단일 실행 동안 고유합니다
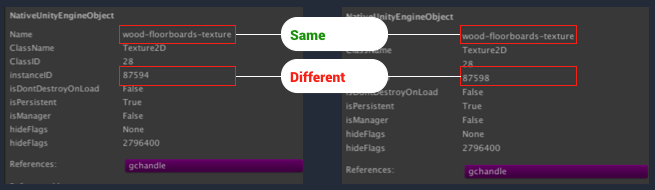
위의 다이어그램은 이 문제의 간단한 예제를 보여줍니다.
다이어그램 왼쪽과 오른쪽에는 메모리 프로파일러 5.4 버전의 세부 정보 창의 스크린샷이 있습니다.
스크린샷에서 보이는 에셋은 메모리에 각각 따로 로드된 두 개의 텍스처입니다.
이 텍스처는 동일한 이름과 용량을 가지고 있으므로, 중복일 수 있습니다.
프로젝트의 “Assets” 폴더를 살펴보면, 그 안에 wood-floorboards-texture 라는 이름을 가진 에셋 파일이 오직 한 개라는 사실을 알 수 있으며, 이는 에셋 중복을 강하게 나타냅니다.
메모리에 있는 각각의 UnityEngine.Object는 고유한 인스턴스 ID가 있으며, 이는 오브젝트가 생성되는 시점에서 할당된 것들입니다.
이들 텍스처는 서로 다른 인스턴스 ID가 있다는 것을 고려했을때, 현재 메모리에는 서로 다른 두 개의 텍스처 데이터 집합이 로드되고 있다는 것을 알 수 있습니다.
파일 이름과 에셋 크기가 동일하며, 인스턴스 ID가 다르므로, 이들 두 오브젝트는 메모리에서 중복된 텍스처를 나타내고 있음을 확실하게 알 수 있습니다
만일 프로젝트에 동일한 파일 이름을 가지는 텍스처가 있는 경우, 이 판단이 절대적이지는 않지만, 동일한 파일 크기인 경우에는 중복되었다고 판단해도 무방합니다.
에셋 번들(AssetBundles) 또는 에셋(Asset) 중복
메모리에 텍스처나 에셋이 중복되는 가장 주된 이유는, 에셋 번들을 부적절하게 언로드하기 때문입니다.
이 문제에 대한 자세한 내용은 유니티의 에셋 번들 베스트 프랙티스를 참조하십시오.
핵심 섹션은 로드된 에셋 관리 입니다.
2.1.2 이미지 버퍼, 이미지 이펙트, RenderTexture 메모리 사용 점검
메모리 비주얼라이저 툴에서 이미지 이펙트나 RenderTexture 오브젝트에 렌더 버퍼를 제공하기 위해 요구되는 메모리를 시각화하는 것 역시 가능합니다.
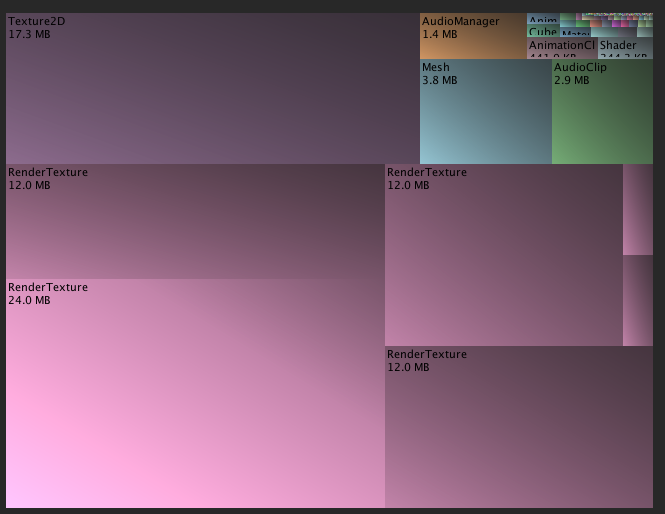
위의 스크린샷은 몇몇 유니티의 시네마틱 이미지 이펙트가 적용된 간단한 씬을 보여주고 있습니다.
이미지 이펙트는 연산을 수행하기 위해서 임시로 렌더 버퍼를 할당합니다.
특히, 블룸 효과는 점점 크기가 작아지는 몇몇 버퍼를 할당합니다.
레티나 iOS 기기는 고해상도 장치이므로, 이러한 임시 버퍼는 프로젝트의 다른 부분보다 상당히 더 많은 양의 메모리를 소모합니다.
iPad Air 2의 경우, 이 태블릿 장치는 2,048x1,536 해상도로 그리게 되는데, 이는 최신 콘솔이나 PC가 목표로 하는 1,080p 해상도 이상입니다.
전체 화면의 임시 렌더 버퍼는 24 또는 36MB의 메모리를 버퍼 포맷에 따라서 소모합니다.
이 값은 렌더 버퍼의 픽셀 치수를 절반으로 줄이는 것으로 그 크기를 75% 감소시킬 수 있습니다.
이렇게 하더라도, 렌더 결과물의 시각적 품질은 그다지 나빠지지는 않습니다.
이미지 이펙트의 임시 렌더 버퍼나 다른 GPU 자원의 사용을 최적화하는 한 방법으로는, 이렇게 서로 분리된 산출 과정을 동시에 수행하는 단일 “uber” 이미지효과를 생성합니다.
Unity 버전 5.5 이상을 사용하는 경우, 새로운 UberFX (github에서 다운로드 가능)패키지를 사용할 수도 있습니다.
이 패키지는 시네마틱 이미지 이펙트가 제공하는 모든 기능을 수행할 수 있고 개별 이미지 이펙트보다 오버헤드가 적으며 설정 가능한 “uber” 이미지 이펙트를 제공합니다.
3. 코루틴
코루틴은 다른 스크립트 코드와 다르게 실행됩니다.
대부분의 스크립트 코드는 단일 위치의 성능 트레이스 내, 특정 Unity 콜백 호출 아래에 나타납니다.
반면, 코루틴의 CPU 코드는 항상 트레이스의 두 곳에서 나타납니다.
코루틴의 모든 시작 코드(코루틴 메서드의 시작부터 첫 번째 yield가 나타나는 곳까지의 코드)는 트레이스에서 나타나고, 트레이스에서 코루틴이 시작됩니다.
보통 StartCoroutine 메서드가 호출되는 곳에서 나타납니다.
유니티 콜백(IEnumerator를 반환하는 Start 콜백 등)에서 생성된 코루틴은 각각의 유니티 콜백에서 최초로 나타납니다.
코루틴의 나머지 모든 코드(즉 다시 재개되는 시점에서부터 실행이 종료될 때까지의 코드)는 유니티 메인 루프에 있는 DelayedCallManager 행에 나타납니다.
왜 이러한 현상이 일어나는지 이해하려면 코루틴이 실제로 어떻게 실행되는지 생각해 보아야 합니다.
코루틴은 C# 컴파일러가 자동으로 생성한 클래스의 인스턴스에 의해 작동합니다.
이 오브젝트는 프로그래머에게 하나로 간주되는 메서드를 여러 번 호출하는 코루틴의 상태를 추적하는 데 필요합니다.
코루틴의 로컬 범위 변수는 yield 호출이 진행되는 동안 유지되어야 하기 때문에 변수는 생성된 클래스에 위치하게 되며, 코루틴이 작동되는 동안 힙에 할당된 상태로 남아 있습니다.
오브젝트는 코루틴의 내부 상태를 추적하여 yield 호출 이후에 코루틴이 재개될 때 코드의 어느 부분부터 재개할 것인지를 기억합니다.
그렇기 때문에 코루틴을 시작할 때 발생하는 메모리 사용량은 고정된 오버헤드 비용에 로컬 범위 변수의 크기를 합한 양과 동일합니다.
코루틴을 시작하는 코드는 이 오브젝트를 생성하고 호출하며, 그 이후 유니티의 DelayedCallManager가 코루틴의 yield 조건이 만족될 때마다 다시 오브젝트를 호출합니다.
코루틴은 보통 다른 코루틴의 외부에서 시작하기 때문에 코루틴 실행 비용은 위에서 설명한 두 위치로 나뉩니다.
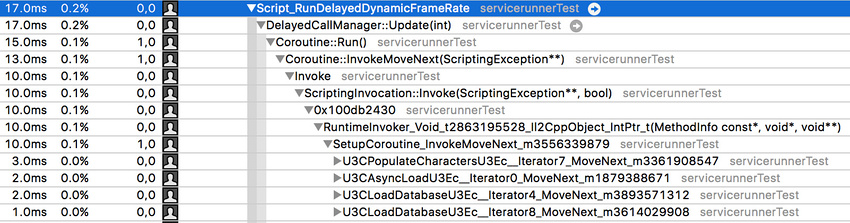
DelayedCallManager가 다수의 다른 코루틴을 재개하는 위 스크린샷에서 이 사실을 관찰할 수 있습니다.
여기서 주요 코루틴은 PopulateCharacters, AsyncLoad, LoadDatabase 등입니다.
가능한 경우 일련의 작업을 최대한 적은 수의 개별 코루틴으로 압축하는 것이 좋습니다.
코루틴을 중첩하면 코드 명료성을 높이고 유지관리가 용이하지만, 코루틴 추적(tracking) 오브젝트로 인해 더 많은 메모리가 소모됩니다.
코루틴이 매 프레임마다 실행되고 오래 실행되는 작업에서 이익이 되지 않는 경우, 일반적으로 코루틴을 Update 또는 LateUpdate 콜백으로 대체하면 더 쉽게 읽을 수 있습니다.
특히 오래 실행되거나 무한 루프되는 코루틴의 경우 더욱 그렇습니다.
코루틴은 오브젝트가 비활성화되더라도 중지되지 않으며 오브젝트가 완전히 소멸될 때에만 중지됩니다.
따라서 코루틴은 계속 실행될 수 있고, 예를 들어 필요한 경우 오브젝트를 다시 활성화할 수도 있습니다.
Destroy(this)를 호출하면 OnDisable이 즉시 트리거되고 코루틴이 처리됩니다.
마지막으로 프레임 끝에서 OnDestroy가 호출됩니다.
코루틴은 스레드가 아니라는 점을 명심하십시오.
코루틴의 동기 작업은 여전히 메인 스레드에서 실행됩니다.
목표가 메인 스레드에서 소비되는 CPU 시간을 줄이는 것이라면 다른 스크립트 코드에서와 마찬가지로 코루틴의 작업 차단을 방지하는 것이 중요합니다.
코루틴은 HTTP 전송, 에셋 로드, 파일 I/O 완료 등을 기다리는 것과 같이 긴 시간을 필요로 하는 비동기 작업에 사용하는 것이 가장 유용합니다.
4. 에셋 검사
실제 프로젝트에서 발생하는 문제는 대부분, 임시로 “테스트”하기 위한 변경을 방치하거나 지친 개발자의 클릭 실수로 성능 저하를 유발하는 에셋을 추가하거나, 기존 에셋의 임포트 설정을 변경하는 등과 같은 명백한 실수에서 비롯됩니다.
상당한 스케일의 프로젝트에서는 인적 오류에 대한 제 1 방어선을 마련하는 것이 가장 좋습니다.
예를 들어, 프로젝트에 압축되지 않은 4K 텍스처를 추가할 수 없도록 하는 짧은 코드를 작성하는 것은 상대적으로 간단합니다.
사실, 이는 놀랍게도 아주 일반적인 문제입니다.
압축되지 않은 4K 텍스처는 60MB 정도의 메모리를 차지합니다.
iPhone 4S와 같은 저사양 모바일 디바이스의 경우, 180–200MB 이상의 메모리를 소모하는 것은 위험합니다.
만일 실수로 추가한 경우, 이 텍스처는 애플리케이션의 가용 메모리 중 1/4–1/3 정도를 의도치않게 차지하게 되며, 이는 진단이 어려운 메모리 부족 오류를 유발합니다.
물론 이러한 문제는 메모리 프로파일러로 발견하여 해결할 수 있기는 하지만, 이러한 문제가 애초에 발생하지 않도록 하는 것이 더 좋습니다.
4.1 AssetPostprocessor 사용
유니티 에디터에서 AssetPostprocessor 클래스는 유니티 프로젝트에 최소한의 기준을 적용하기 위해 사용할 수 있습니다.
이 클래스는 에셋을 가져오는 동안 콜백을 받습니다.
클래스를 사용하려면, AssetPostprocessor에서 상속받은 이후, 한 개 이상의 OnPreprocess 메서드를 구현합니다.
다음의 메서드들이 흔히 사용됩니다.
- OnPreprocessTexture
- OnPreprocessModel
- OnPreprocessAnimation
- OnPreprocessAudio
사용할 수 있는 더 많은 OnPreprocess 메서드는 AssetPostprocessor 페이지의 스크립팅 레퍼런스를 참조하십시오.
public class ReadOnlyModelPostprocessor : AssetPostprocessor
{
public void OnPreprocessModel()
{
ModelImporter modelImporter = (ModelImporter)assetImporter;
if(modelImporter.isReadable)
{
modelImporter.isReadable = false;
modelImporter.SaveAndReimport();
}
}
}
위의 간단한 예제는 프로젝트에서 AssetPostprocessor가 어떻게 규칙을 적용하는지 보여줍니다.
이 클래스는 프로젝트에 모델을 임포트하거나, 모델의 임포트 설정이 변경될 때마다 호출됩니다.
코드는 Read/Write enabled 플래그(isReadable 프로퍼티)가 true로 설정되어 있는지 단순히 확인합니다.
만약 true인 경우에는 플래그를 강제로 false로 바꾸어 저장한 후, 에셋을 다시 임포트합니다.
여기서 SaveAndReimport 메서드를 호출하면, 코드 조각이 다시 호출됩니다.
하지만, 이제 isReadable의 값은 false이므로, 이 코드로 인하여 무한 임포트 루프를 발생시키지 않습니다.
왜 이러한 변경이 일어나는지에 대한 이유는 아래의 “모델” 섹션에 설명되어 있습니다.
4.2 일반적인 에셋(Asset) 규칙
4.2.1 텍스처(Textures)
① Read/Write enabled 플래그 비활성화
Read/Write enabled 플래그는 텍스처가 메모리에서 한 번은 GPU, 한 번은 CPU가 접근 가능한 메모리, 이렇게 두 번 메모리에 저장되게 합니다.
이는 대부분 플랫폼의 경우, GPU 메모리로부터 리드백(되읽기)을 하는 것은 매우 느리기 때문입니다. GPU 메모리에서 텍스처를 CPU 코드(Texture.GetPixel 등)가 사용할 임시 버퍼로 읽어 들이는 것은 대단히 비효율적입니다.
유니티에서 기본적으로 이 설정이 비활성화되어 있기는 하지만, 실수로 이 설정이 활성화될 수 있습니다.
Read/Write Enabled 플래그는 셰이더 외부(Texture.GetPixel나 Texture.SetPixel API 등)에서 텍스처 데이터를 조작할 때만 필요합니다.
이를 제외하고는 최대한 사용을 피하십시오.
② 가능한 경우 밉맵 비활성화
카메라에 대해서 상대적으로 변동이 적은 Z 뎁스를 가지는 오브젝트의 경우, 밉맵을 비활성화하면 텍스처를 로드하는 데 필요한 메모리의 약 1/3 정도를 절약할 수 있습니다.
하지만 만일 오브젝트가 Z 뎁스를 변화시키는 경우에는, 밉맵을 비활성화하면 GPU에서 텍스처 샘플링 성능이 저하될 수도 있습니다.
일반적으로 화면에서 일정한 크기로 표시되는 UI 텍스처나 기타 텍스처의 밉맵을 비활성화 하는 것이 좋습니다.
③ 모든 텍스처를 압축
프로젝트의 타겟 플랫폼에 적합한 텍스처 압축 포맷을 사용하면 메모리를 크게 절약할 수 있습니다.
만약 선택된 텍스처 압축 포맷이 타겟 플랫폼에 적합하지 않은 경우, 유니티는 텍스처가 로드될 때 이를 압축 해제하며, 막대한 CPU 사용 시간과 메모리를 차지합니다.
이는 칩셋에 따라 상당히 다른 텍스처 압축 포맷을 지원하는 Android 디바이스에서 가장 흔히 발생하는 문제입니다.
④ 적절한 텍스처 크기 제한 적용
텍스처 크기를 조절하는 것을 잊거나, 의도치않게 텍스처 크기 임포트 설정을 변경하는 일은 아주 흔합니다.
이를 방지하기 위해서, 서로 다른 텍스처 타입마다 적절한 최대 크기를 설정하고, 이를 코드를 통해서 적용하도록 하십시오.
많은 모바일 애플리케이션의 경우, 텍스처 아틀라스의 경우에는 2,048x2,048 또는 1,024x1,024, 3D 모델에 적용되는 텍스처의 경우에는 512x512면 충분합니다.
4.2.2 모델
① Read/Write enabled 플래그 비활성화
Read/Write enabled 플래그는 모델의 경우에도 텍스처 에 대해 설명한 것과 동일하게 동작합니다.
하지만, 모델의 경우에는 기본적으로 활성화되어 있습니다.
만일 프로젝트가 스크립트를 통하여 런타임 시점에 메시를 수정하거나, 메시가 MeshCollider 컴포넌트의 기반으로 사용되는 경우, 유니티에서 이 플래그를 활성화해야 합니다.
만일 모델이 MeshCollider에서 사용되지 않고, 스크립트에서 수정되지 않는 경우, 이 플래그는 비활성화될 수 있으며, 모델이 차지하는 메모리가 절반 가량 절약됩니다.
② 캐릭터 모델에서 리그 비활성화
기본적으로 유니티는 비캐릭터 모델의 경우에는 제네릭 릭을 가져옵니다.
이는 모델이 런타임 시점에 인스턴스화되는 경우, Animator 컴포넌트가 더해지게 됩니다.
만약 모델이 애니메이션 시스템을 통해서 애니메이션화되는 것이 아니라면, 모든 활성화된 애니메이터는 프레임당 한 번씩 동작되어야 하므로, 애니메이션 시스템에 불필요한 부하를 주게 됩니다.
Animator 컴포넌트의 자동 추가와 원치 않는 애니메이터를 씬에 실수로 추가할 가능성을 방지하기 위해, 애니메이션화되지 않는 모델의 리그를 비활성화합니다.
③ 애니메이션화 되는 모델에 게임 오브젝트 최적화 옵션 활성화
Optimize Game Objects 옵션은 애니메이션화된 모델의 성능에 상당한 영향을 줍니다.
만일 이 옵션이 비활성화 된 경우, 유니티는 모델이 인스턴스화될 때마다 모델의 골격 구조를 복제하는 거대한 트랜스폼 계층 구조를 생성합니다.
이 트랜스폼 계층 구조는 업데이트하는 데 비용이 많이 들며, 특히 다른 컴포넌트(Particle Systems이나 Colliders)가 부착된 경우 더욱 부담이 됩니다.
또한, 멀티스레드 메시 스키닝이나 본 애니메이션 계산에 대한 유니티의 성능을 제한합니다.
만약 모델의 골격 구조의 특정 위치가 노출되어야 하는 경우(동적으로 무기 모델을 부착할 수 있도록 모델의 손을 노출하는 경우 등), 이러한 위치는 Extra Transforms 리스트에 따로 추가할 수도 있습니다.
자세한 내용은 유니티 매뉴얼의 모델 임포터 페이지를 참조하십시오.
④ 가능한 한 메시 압축 사용
메시 압축을 활성화하면, 모델 데이터의 다른 채널들에 대한 부동 소숫점 수를 나타내는데 사용되는 비트 수를 줄여줍니다.
이는 정밀도가 약간 손상될 수 있으며 최종 프로젝트에서 사용하기 전에 이 부정확성의 영향을 아티스트가 확인해야 합니다.
압축 수준에 따른 비트 수의 정확한 값은 ModelImporterMeshCompression 스크립팅 레퍼런스를 참조하십시오.
채널마다 서로 다른 압축 수준을 사용할 수도 있으므로, 프로젝트에서 UV와 정점 포지션을 압축하지 않고 탄젠트와 노멀만 압축하도록 선택할 수 있습니다.
⑤ 메시 렌더러 설정
프리팹 또는 게임 오브젝트에 메시 렌더러를 추가할 경우, 컴포넌트의 설정을 눈여겨 보십시오.
기본적으로 유니티는 섀도우 캐스팅과 받기, 라이트 프로브 샘플링, 반사 프로브 샘플링, 모션 벡터 계산을 활성화합니다.
만약 프로젝트에서 이들 기능 중 하나 이상 필요로 하지 않는 경우, 자동화된 스크립트를 통하여 이를 비활성화합니다.
마찬가지로 런타임 시 MeshRenderer를 추가하는 코드에서도 이 세팅을 켜거나 꺼야합니다.
2D 게임에서 그림자 옵션을 켠 상태에서 씬에 MeshRenderer를 실수로 추가하게 되면, 전체 그림자가 렌더링 루프에 전달됩니다.
이는 일반적으로 성능 낭비가 됩니다.
4.2.3 오디오(Audio)
① 플랫폼에 적합한 압축 설정
사용 가능한 하드웨어에 부합하는 오디오 압축 포맷을 사용합니다.
모든 iOS 장치는 MP3 하드웨어 압축 해제가 가능하며, 다수의 Android 디바이스는 기본적으로 Vorbis를 지원합니다.
이와 더불어, 유니티에 비압축 오디오 파일을 가져오십시오.
유니티는 항상 프로젝트를 빌드하는 동안 오디오 파일을 다시 압축합니다.
따라서 압축된 오디오를 가져와서 다시 압축할 필요는 없습니다.
이는 최종 오디오 클립의 품질을 낮출 뿐입니다.
② 오디오 클립을 모노로 설정
소수의 모바일 디바이스만이 스테리오 스피커를 지원합니다.
따라서 모바일 프로젝트의 경우, 임포트한 오디오 클립을 모노 채널로 강제로 설정하면 메모리 소비를 절반으로 줄일 수 있습니다.
이 설정은 대부분의 UI 음향 효과와 같이, 스테리오 효과가 없는 오디오 클립의 경우에도 적용할 수 있습니다.
③ 오디오 비트레이트 축소
물론 이는 오디오 디자이너와 상의해야 하지만, 오디오 파일의 비트레이트를 최소화하는 경우 메모리 소비와 빌드된 프로젝트의 크기를 더욱 줄일 수 있습니다.
5. 관리되는 힙에 대한 이해
많은 유니티 개발자들이 겪는 또 다른 일반적인 문제는 예기치 않은 관리되는 힙(managed heap)의 확장입니다.
유니티에서 관리되는 힙은 축소되는 것보다 더 쉽게 확장됩니다.
이와 더불어, 유니티의 가비지 컬렉션 전략은 메모리를 프래그먼트하는 경향이 있는데, 이는 크기가 큰 힙이 줄어드는 것을 방해할 수 있습니다.
5.1 관리되는 힙의 작업 방식 및 확장 이유
“관리되는 힙”은 프로젝트의 스크립팅 런타임(Mono 또는 IL2CPP) 메모리 관리자가 자동으로 관리하는 메모리 부분입니다.
관리 코드에 생성된 모든 오브젝트는 관리되는 힙에 할당되어야 합니다.
엄격히 말하면 모든 null 참조를 하지 않는 타입의 오브젝트와 박스 값 타입의 오브젝트가 관리되는 힙에 할당되어야 합니다

위 다이어그램에서 흰 상자는 관리되는 힙에 할당된 메모리의 용량을 나타내며, 그 안의 색칠된 상자는 관리되는 힙의 메모리 공간에 저장된 데이터 값을 나타냅니다.
만일 추가 값들이 필요한 경우에는, 관리되는 힙에서 더 많은 공간이 할당됩니다.
가비지 컬렉터는 일정 시간마다 실행됩니다.
정확한 실행 간격은 플랫폼마다 서로 다릅니다
이는 힙의 모든 오브젝트에 대해 정리하고, 더 이상 레퍼런스하지 않는 모든 오브젝트를 삭제하도록 표시합니다.
이후 레퍼런스하지 않는 오브젝트는 삭제되어 메모리를 확보합니다.
여기서 중요한 사실은 유니티 가비지 컬렉션은 Boehm GC 알고리즘을 사용하며, 이는 비세대 기반이고 비압축화 되어있다는 것 입니다.
여기서 “비세대 기반”은 콜렉션 패스를 진행하는 동안 가비지 컬렉터(GC)는 힙 전체를 정리해야 한다는 것을 의미하며, 따라서 GC의 성능은 힙이 확장되는 경우 감소합니다.
“비압축화”는 오브젝트간 간극을 줄일 수 있도록 메모리의 오브젝트를 재배치하는 과정이 일어나지 않는다는 의미입니다.

위의 다이어그램은 메모리 단편화의 예제입니다.
오브젝트가 해제되면 오브젝트가 점유하던 메모리는 다시 반환됩니다.
하지만, 반환된 공간은 즉시 “사용 가능한 메모리”라는 단일 풀에 속하지는 않습니다.
해제된 오브젝트의 양쪽에 위치한 오브젝트가 사용 중일 수 있기 때문입니다.
이로 인하여, 반환된 공간은 사용 중인 메모리 세그멘트 간 “간극”이 됩니다
이 간극은 다이어그램 상으로는 빨간색 원으로 나타납니다.
따라서 반환된 공간은 해제된 오브젝트의 용량과 같거나 적은 데이터를 저장하는 데에만 사용할 수 있습니다.
오브젝트를 할당할 때, 오브젝트는 항상 연속된 메모리 공간을 차지해야 한다는 것을 기억하십시오.
이는 메모리 단편화의 핵심 문제를 유발합니다.
힙에 존재하는 사용 가능한 메모리 양 자체는 상당할 수 있지만, 정작 사용 가능한 공간은 할당된 오브젝트 사이의 “간극”으로 구성되어 있을 수도 있습니다.
이 경우 어떤 오브젝트를 할당할 공간은 전체적으로 충분하지만, 관리되는 힙에서 그 오브젝트를 저장할 수 있는 연속된 공간을 찾지 못할 수 있습니다.

하지만, 만일 용량이 큰 오브젝트가 할당되었으나 이를 수용할 만한 충분한 크기의 연속된 공간이 없는 경우 위에서 보이는 것과 같이, 유니티 메모리 관리자는 두 개의 작업을 실행합니다.
우선, 가비지 컬렉터가 아직 실행되지 않은 경우 이를 실행시킵니다.
이는 할당 요청을 수용할 수 있는 충분한 공간을 만들 수 있도록 시도합니다.
가비지 컬렉터가 실행된 이후에도 요청된 메모리 공간을 수용할 수 있는 연속된 공간이 없는 경우에는 힙을 확장시킵니다.
힙이 확장되는 정도는 플랫폼에 따라 다르지만, 대부분의 유니티 플랫폼의 경우 관리되는 힙의 크기를 두 배로 늘립니다.
5.2 힙의 주요 문제점
관리되는 힙의 핵심 이슈는 다음과 같이 크게 두 개가 있습니다.
- 유니티는 관리되는 힙이 확장되는 경우, 그에 할당된 메모리 페이지는 주로 해제하지 않습니다. 관리되는 힙의 상당 부분이 빈 경우에도 확장된 힙 부분을 그대로 유지합니다. 이는 좀더 큰 할당이 발생해도 힙을 다시 확장해야 할 필요가 없도록 하기 위한 것입니다.
- 대부분의 플랫폼에서 유니티는 결국 관리되는 힙의 빈 부분이 차지하는 페이지를 해제하여 다시 운영체제에 릴리스하지만, 해제가 되는 간격은 정확하지 않으므로 이에 종속해서는 안됩니다.
- 관리되는 힙이 사용하는 주소 공간은 절대로 운영체제에 반환되지 않습니다.
- 32비트 프로그램에서 관리되는 힙이 반복해서 확장하고 수축하면, 주소 공간이 부족해지는 경우가 발생할 수 있습니다. 만일 프로그램이 사용 가능한 메모리 주소 공간이 부족해지는 경우 운영체제는 해당 프로그램을 종료합니다.
- 반면 64비트 프로그램의 경우 주소 공간은 충분히 확보되어 있으므로, 사용자가 평생 프로그램을 실행시킨다 하더라도 위의 상황이 발생할 가능성은 거의 없습니다.
5.3 임시 할당
많은 유니티 프로젝트에서 매 프레임마다 수십 또는 수백 KB의 임시 데이터를 관리되는 힙에 할당하며 동작하는 것이 발견됩니다.
이는 프로젝트 성능에 상당한 악영향을 줄 수 있습니다.
아래의 계산을 참조하십시오.
만일 프로그램이 각 프레임마다 1KB 만큼의 임시 메모리를 할당하고, 초당 프레임 수가 60인 경우, 프로그램은 1초당 60KB 만큼의 임시 메모리를 할당해야 합니다.
1분이 지나면 메모리에 가비지가 3.5MB까지 추가됩니다.
가비지 컬렉터를 매초마다 호출하는 것은 성능에 악영향을 줄 수 있습니다만 매 분당 3.6MB를 할당하는 것은 메모리가 부족한 디바이스에서 실행하려고 할 때 문제가 됩니다.
또한, 로딩 작업을 고려하십시오.
만일 용량이 큰 에셋을 로드하는 작업 동안 다수의 임시 오브젝트가 생성되고, 오브젝트는 작업이 완료되기 전까지 레퍼런스된다고 가정하면, 가비지 컬렉터는 이들 임시 오브젝트를 릴리스할 수 없습니다.
그리고 비록 힙에 있는 많은 오브젝트가 잠시 후에 해제되더라도 관리되는 힙은 확장되어야 합니다.
관리 메모리 할당을 트래킹하는 것은 비교적 간단합니다.
유니티의 CPU 프로파일러의 개요 창에는 “GC Alloc” 열이 있습니다.
이 열은 특정 프레임에서 관리되는 힙에 할당된 용량을 바이트 단위로 나타냅니다.
이는 주어진 프레임 동안 일시적으로 할당된 용량과 동일하지는 않습니다.
할당된 메모리의 전체 또는 일부가 이후 프레임에서 재사용된다고 하더라도 이 프로파일은 특정 프레임에 할당된 바이트 수를 표시합니다
“Deep Profiling” 옵션이 활성화된 경우, 이러한 할당이 발생하는 메서드를 트래킹할 수 있습니다.
메인 스레드에서 발생하는 경우에만 유니티 프로파일러는 이러한 할당을 트래킹합니다.
따라서 “GC Alloc” 열은 사용자가 생성한 스레드에서 발생하는 관리되는 할당을 측정하는 데 사용할 수 없습니다.
디버깅 용도일 경우 코드 실행을 별도의 스레드에서 메인 스레드로 전환하십시오.
타임라인 프로파일러에서 샘플을 표시하려면 BeginThreadProfiling API를 사용합니다.
대상 기기에서 항상 개발 빌드 옵션을 설정하고 관리되는 메모리 할당을 프로파일링합니다.
일부 스크립트 메서드는 에디터에서 실행될 때 할당을 하지만, 프로젝트가 빌드된 이후에는 할당을 하지 않는다는 점을 주목하십시오.
GetComponent 메서드가 가장 일반적인 예입니다.
메서드는 에디터에서 실행될 때 항상 힙을 할당하지만, 빌드된 프로에서는 할당하지 않습니다.
일반적으로, 프로젝트가 상호작용하는 상태인 경우에는 관리되는 힙 할당을 최소화하는 것을 강력히 추천합니다.
씬 로딩과 같이 상호작용이 없는 작업 중 할당하는 것은 문제의 소지가 비교적 적습니다.
Visual Studio용 Jetbrains Resharper Plugin을 이용하면 코드에서 할당 위치를 검색할 수 있습니다.
유니티의 세부 프로파일링(Deep Profile) 모드를 사용하여 관리되는 할당의 특정 원인을 검색할 수 있습니다.
Deep Profile 모드에서는 모든 메서드 호출이 개별적으로 기록되어 메서드 호출 트리 내에서 관리되는 할당이 발생하는 위치를 보다 명확하게 확인할 수 있습니다.
Deep Profile 모드는 에디터뿐 아니라 커맨드 라인 인자 -deepprofiling을 사용할 경우 Android 및 데스크톱에서도 안정적으로 작동합니다.
Deep Profiler 버튼은 프로파일링이 진행되는 동안 회색으로 표시됩니다.
5.4 메모리 보존의 기본
관리되는 힙 할당을 줄이기 위해 사용할 수 있는 비교적 단순한 기법들이 있습니다.
5.4.1 컬렉션과 배열 재사용
C# 컬렉션 클래스나 배열을 사용하는 경우, 가능하면 할당된 컬렉션이나 배열을 재사용하거나 풀링하는 것을 고려해 보십시오.
컬렉션 클래스는 컬렉션의 값을 제거하지만, 컬렉션에 할당된 메모리는 해제하지 않는 Clear 메서드를 가지고 있습니다.
void Update()
{
List<float> nearestNeighbors = new List<float>();
findDistancesToNearestNeighbors(nearestNeighbors);
nearestNeighbors.Sort();
// … use the sorted list somehow …
}
이는 복잡한 연산에 임시 “helper” 컬렉션 메서드를 할당할 때 특히 유용합니다.
다음은 이에 관련된 간단한 예제입니다.
이 예제에서는, nearestNeighbors 리스트가 프레임당 한 번 할당되어 데이터 포인트 집합을 수집합니다.
이 리스트를 메서드 밖으로 빼서 이것을 가지고 있는 클래스로 옮기는 것은 아주 단순하며, 매 프레임마다 새로운 리스트를 할당하는 것을 방지합니다.
List<float> m_NearestNeighbors = new List<float>();
void Update()
{
m_NearestNeighbors.Clear();
findDistancesToNearestNeighbors(NearestNeighbors);
m_NearestNeighbors.Sort();
// … use the sorted list somehow …
}
이 예제에서는 리스트의 메모리가 계속 유지되고 여러 프레임 동안 재사용되는 것을 볼 수 있습니다.
새로운 메모리 공간은 오직 리스트가 확장되어야 하는 경우에만 할당됩니다.
5.5 클로저 및 익명 메서드
클로저와 익명 메서드를 사용하는 경우, 크게 두 가지를 고려해야 합니다.
첫째, C#의 메서드 레퍼런스는 전부 레퍼런스 타입이므로, 이는 힙에 할당됩니다.
메서드 참조를 인수로 전달하는 것으로 쉽게 임시 할당이 생성될 수 있습니다.
이런 할당은 전달되는 메서드가 익명 메서드인지 미리 정의된 것인지에 관계없이 발생합니다.
둘째로, 익명 메서드를 클로저로 전환하는 것은 이를 수용하는 메서드에 클로저를 전달하는 데 필요한 메모리 용량을 상당히 증가시킵니다.
다음의 코드를 살펴보겠습니다
List<float> listOfNumbers = createListOfRandomNumbers();
listOfNumbers.Sort( (x, y) =>
(int)x.CompareTo((int)(y/2))
);
이 코드 조각은 첫 줄에서 생성된 숫자 리스트의 정렬 순서를 관리하는 단순한 익명 메서드를 사용하고 있습니다.
하지만, 만약 프로그래머가 이 코드 조각을 다시 사용할 수 있도록 하려면, 다음과 같이 상수 2를 로컬 범위의 변수로 대체하는 것이 좋아 보입니다.
List<float> listOfNumbers = createListOfRandomNumbers();
int desiredDivisor = getDesiredDivisor();
listOfNumbers.Sort( (x, y) =>
(int)x.CompareTo((int)(y/desiredDivisor))
);
이제 이 익명 메서드는 메서드 범위 밖의 변수 상태에 접근할 수 있어야 하므로 클로저가 되었습니다.
desiredDivisor 변수를 이 클로저에서 사용할 수 있으려면 해당 변수를 어떻게든 클로저에게 전달해야 합니다.
이를 위해서 C#은 클로저에 필요한 외부 범위 변수를 유지할 수 있는 익명 클래스를 생성합니다.
이 클래스의 사본은 클로저가 Sort 메서드에 전달될 때 인스턴스화되며, desiredDivisor 정수의 값으로 초기화됩니다.
이 클로저를 실행하려면 생성된 클래스 사본의 인스턴스화가 필요하고, 모든 클래스가 C# 참조 형식이므로, 클로저를 실행하기 위해서는 관리되는 힙에 오브젝트를 할당해야 합니다.
일반적으로 가능하면 C#에서는 클로저를 피하는 것이 가장 좋습니다.
익명 메서드와 메서드 참조는 성능에 민감한 코드, 특히 프레임 단위로 실행되는 코드에서 최소화 돼야합니다.
5.5.1 IL2CPP 하의 익명 메서드
현재 IL2CPP가 생성한 코드를 살펴보면, System.Function 변수의 단순 선언과 할당이 새로운 오브젝트를 할당하는 것을 알 수 있습니다.
이는 변수가 명시적(메서드나 클래스에서 선언된 경우)이든 암시적(다른 메서드에 인수로서 선언된 경우)이든 무관합니다.
따라서 IL2CPP 스크립팅 백엔드 하에서 익명 메서드를 사용하는 경우, 관리되는 메모리를 할당합니다.
Mono 스크립팅 백엔드의 경우에는 그렇지 않습니다.
또한, IL2CPP는 메서드 인수가 선언된 방식에 따라 관리되는 메모리 할당 수준이 아주 다르게 나타납니다.
예상대로 클로저는 호출당 최대 메모리를 할당합니다.
비직관적이지만, 미리 정의된 메서드는 IL2CPP 스크립팅 백엔드 하에서 인수로 패스될 때 클로저만큼 메모리 를 할당합니다.
익명 메서드는 힙에 일시적인 가비지를 한 자릿수 이상으로 최소한의 양만큼 생성합니다.
따라서 만일 프로젝트가 IL2CPP 스크립팅 백엔드로 출시되는 경우, 아래와 같이 세 가지 사항을 추천합니다.
- 메서드를 인수로서 전달할 필요가 없는 코딩 스타일을 선호합니다.
- 반드시 써야한다면 미리 정의된 메서드보다는 익명 메서드를 선택합니다.
- 스크립팅 백엔드의 타입과 무관하게, 클로저를 최대한 피하십시오.
5.6 박싱
박싱은 유니티 프로젝트에서 의도하지 않은 임시 메모리 할당이 발생하는 가장 주된 원인입니다.
이는 값 타입의 값이 레퍼런스 타입으로 활용될 때마다 발생하며, 특히 기본적인 값 형식 변수(int나 float 등)를 오브젝트 형식의 메서드로 전달할 때 주로 발생합니다.
아래의 아주 간단한 예제에서 x 의 정수가 object.Equals 메서드에 전달될 수 있도록 박싱이 일어나는데, object 의 Equals 메서드는 object가 전달되어야 하기 때문입니다.
int x = 1;
object y = new object();
y.Equals(x);
보통 C# IDE와 컴파일러는 의도하지 않은 메모리 할당으로 이어지는 경우에도, 박싱에 대한 경고를 표시하지 않습니다.
이는 C# 언어가 소규모 임시 메모리 할당은 효율적으로 세대 기반 가비지 컬렉터와 할당 크기에 민감한 메모리 풀을 활용하여 해결할 수 있을 것이라는 전제 아래 개발되었기 때문입니다.
유니티할당자는 크고 작은 메모리 할당을 해결하기 위해 서로 다른 메모리 풀을 활용하기는 하지만, 유니티 가비지 컬렉터는 세대 기반이 아니며 따라서 박싱이 생성하는 소규모의 빈번한 임시 할당을 효율적으로 제거할 수 없습니다.
유니티 런타임용 C# 코드를 작성할 경우, 박싱(boxing)을 최대한 피해야 합니다.
5.6.1 박싱의 식별
박싱은 CPU 트레이스에서, 사용하는 스크립팅 백엔드에 따라 여러 개의 메서드 중 하나를 호출되는 형식으로 나타납니다.
이는 일반적으로 다음과 같은 형식을 가집니다.
여기서 <some class>는 다른 클래스나 구조체의 이름을 의미하며, …는 인수를 의미합니다.
- <some class>::Box(…)
- Box(…)
- <some class>_Box(…)
또한 ReSharper나 dotPeek 디컴파일러에 내장된 IL 뷰어 툴과 같은 디컴파일러나 IL 뷰어의 결과물을 검색하여 박싱을 식별할 수도 있습니다.
IL 명령어는 “box”입니다.
5.6.2 딕셔너리(Dictionaries) 및 열거형(enums)
박싱이 발생하는 흔한 원인 중 하나는 enum 타입을 Dictionary의 키로 사용하는 것입니다.
enum을 선언하는 것은 씬 내부에서 정수로 취급되는 새로운 값 타입을 생성하나, 컴파일 시간 동안에는 형식 안전성 규칙을 집행합니다.
기본적으로 Dictionary.add(key, value)를 호출하면 Object.getHashCode(Object)가 호출됩니다.
이 메서드는 Dictionary의 키에 적절한 해시 코드를 얻기 위해서 사용되며 Dictionary.tryGetValue, Dictionary.remove 등과 같이 키를 허용하는 모든 메서드에서 사용됩니다.
Object.getHashCode 메서드는 참조 형식이지만, enum 값은 항상 값 형식입니다.
따라서 열거형 키를 가지는 Dictionary의 경우, 모든 메서드 호출은 최소한 한 번씩은 키를 박싱합니다.
아래의 코드 조각은 이러한 박싱 문제를 보여주는 간단한 예제입니다.
enum MyEnum { a, b, c };
var myDictionary = new Dictionary<MyEnum, object>();
myDictionary.Add(MyEnum.a, new object());
이 문제를 해결하려면 IEqualityComparer 인터페이스를 구현하는 사용자 정의 클래스를 작성하고, 그 클래스의 인스턴스를 Dictionary의 비교자로 할당하면 됩니다
이 오브젝트는 보통 무소속이므로, 메모리를 절약하기 위해 다른 Dictionary 인스턴스에 대해서도 사용할 수 있습니다.
다음은 위의 코드 조각에 사용할 수 있는 IEqualityComparer의 간단한 예제입니다.
public class MyEnumComparer : IEqualityComparer<MyEnum>
{
public bool Equals(MyEnum x, MyEnum y)
{
return x == y;
}
public int GetHashCode(MyEnum x)
{
return (int)x;
}
}
위 클래스의 인스턴스는 Dictionary의 생성자로 전달될 수도 있습니다.
5.7 Foreach 루프
Mono C# 컴파일러의 유니티 버전에서는, foreach 루프를 사용하는 경우 각각의 루프가 종료되는 시점 마다 유니티가 값을 강제로 박싱하게 합니다
루프 전체의 실행이 완료된 이후에 해당 값이 한 번씩 박싱됩니다.
루프가 반복될 때마다 박싱을 하지는 않기에, 루프가 2번 반복하든, 200번 반복하든 메모리 사용량은 같습니다.
이는 Unity C# 컴파일러가 생성한 IL이 값 수집을 반복할 수 있도록 일반적인 값 형식의 열거자(Enumerator)를 생성하기 때문입니다.
이 열거자는 루프가 종료되는 시점에 호출되어야 하는 IDisposable 인터페이스를 구현합니다.
하지만, 값 형식의 오브젝트(구조체나 열거자 등)에서 인터페이스 메서드를 호출하려면, 오브젝트를 박싱해야 합니다.
다음의 아주 단순한 예제 코드를 생각해 보십시오.
int accum = 0;
foreach(int x in myList)
{
accum += x;
}
위의 코드가 유니티의 C# 컴파일러를 통해 실행된 경우에는 다음의 중간 언어로 작성된 코드가 생성됩니다.
.method private hidebysig instance void
ILForeach() cil managed
{
.maxstack 8
.locals init (
[0] int32 num,
[1] int32 current,
[2] valuetype [mscorlib]System.Collections.Generic.List`1/Enumerator<int32> V_2
)
// [67 5 - 67 16]
IL_0000: ldc.i4.0
IL_0001: stloc.0 // num
// [68 5 - 68 74]
IL_0002: ldarg.0 // this
IL_0003: ldfld class [mscorlib]System.Collections.Generic.List`1<int32> test::myList
IL_0008: callvirt instance valuetype [mscorlib]System.Collections.Generic.List`1/Enumerator<!0/*int32*/> class [mscorlib]System.Collections.Generic.List`1<int32>::GetEnumerator()
IL_000d: stloc.2 // V_2
.try
{
IL_000e: br IL_001f
// [72 9 - 72 41]
IL_0013: ldloca.s V_2
IL_0015: call instance !0/*int32*/ valuetype [mscorlib]System.Collections.Generic.List`1/Enumerator<int32>::get_Current()
IL_001a: stloc.1 // current
// [73 9 - 73 23]
IL_001b: ldloc.0 // num
IL_001c: ldloc.1 // current
IL_001d: add
IL_001e: stloc.0 // num
// [70 7 - 70 36]
IL_001f: ldloca.s V_2
IL_0021: call instance bool valuetype [mscorlib]System.Collections.Generic.List`1/Enumerator<int32>::MoveNext()
IL_0026: brtrue IL_0013
IL_002b: leave IL_003c
} // end of .try
finally
{
IL_0030: ldloc.2 // V_2
IL_0031: box valuetype [mscorlib]System.Collections.Generic.List`1/Enumerator<int32>
IL_0036: callvirt instance void [mscorlib]System.IDisposable::Dispose()
IL_003b: endfinally
} // end of finally
IL_003c: ret
} // end of method test::ILForeach
} // end of class test
여기서 가장 연관있는 코드는 후반부에 있는 __finally { … }__ 블록입니다.
callvirt 명령은 메서드를 호출하기 이전 메모리에 있는 IDisposable.Dispose 메서드의 위치를 파악하며, 이는 열거자(Enumerator)가 박싱되어야 실행할 수 있습니다.
일반적으로 유니티에서는 foreach 루프를 피하는 것이 좋습니다.
이 루프는 박싱을 할 뿐만 아니라, 열거자를 통해 콜렉션을 반복하는 메서드 호출 비용은 for나 while 루프를 사용하는 수동 반복보다 일반적으로 훨씬 느립니다.
유니티 버전 5.5에서는 C# 컴파일러가 업그레이드되어, IL을 생성하는 기능이 크게 개선되었습니다.
특히, foreach 루프에서 발생하던 박싱 작업이 제거되었으며, 이는 foreach 루프와 관련된 메모리 오버헤드를 제거합니다.
하지만 메서드 호출 오버헤드로 인하여, 동일한 배열(Array) 기반 코드와 비교했을 때 아직 CPU 성능은 차이가 있습니다.
5.8 배열 기반 Unity API
배열을 리턴하는 Unity API를 반복해서 액세스하는 것은 불필요한 배열 할당을 유발하는 원인 중의 하나로 치명적이지만 눈에 잘 띄지는 않습니다.
배열을 리턴하는 모든 Unity API는 액세스할 때마다 배열의 새로운 사본을 생성합니다.
따라서 배열 기반의 Unity API를 필요 이상으로 액세스하는 것은 대단히 비효율적입니다.
아래 예제에서는 루프 반복마다 네 개의 vertices 배열 사본을 불필요하게 생성하고 있음을 볼 수 있습니다.
이러한 할당 작업은 .vertices 프로퍼티에 액세스할 때마다 매번 실행됩니다.
for(int i = 0; i < mesh.vertices.Length; i++)
{
float x, y, z;
x = mesh.vertices[i].x;
y = mesh.vertices[i].y;
z = mesh.vertices[i].z;
// ...
DoSomething(x, y, z);
}
이는 아래와 같이 루프에 들어가기 전에, .vertices 배열을 캡처함으로써 루프 반복 횟수와 무관하게 단일 배열 할당으로 간단하게 바꿀 수 있습니다.
var vertices = mesh.vertices;
for(int i = 0; i < vertices.Length; i++)
{
float x, y, z;
x = vertices[i].x;
y = vertices[i].y;
z = vertices[i].z;
// ...
DoSomething(x, y, z);
}
프로퍼티를 한 번 액세스하는 CPU 비용은 그렇게 크지는 않지만, 루프에 계속해서 액세스하면 CPU 성능을 크게 차지합니다. 반복적인 액세스는 관리되는 힙을 불필요하게 확장합니다.
이 문제는 모바일 디바이스에서 자주 나타나는데, 이는 Input.touches API가 위의 예제와 비슷하게 실행되기 때문입니다.
.touches 프로퍼티가 액세스될 때마다 할당이 발생하는 것과 같이, 프로젝트에 다음과 같은 코드가 있는 일은 대단히 흔합니다.
for ( int i = 0; i < Input.touches.Length; i++ )
{
Touch touch = Input.touches[i];
// …
}
물론, 이는 다음과 같이 배열 할당을 루프 조건 밖으로 빼는 것으로 간단하게 개선할 수 있습니다.
Touch[] touches = Input.touches;
for ( int i = 0; i < touches.Length; i++ )
{
Touch touch = touches[i];
// …
}
하지만, 메모리 할당을 유발하지 않는 많은 종류의 Unity API가 있습니다. 가능하면 이들을 주로 사용합니다.
int touchCount = Input.touchCount;
for ( int i = 0; i < touchCount; i++ )
{
Touch touch = Input.GetTouch(i);
// …
}
위의 예제를 할당이 적은 Touch API로 전환하는 것은 간단합니다.
프로퍼티의 get 메서드를 호출하는 CPU 비용을 절약하기 위해서, 프로퍼티 접근(Input.touchCount)은 루프 조건 외부에 위치하고 있습니다.
5.8.1 빈 배열 재사용
몇몇 개발팀은 배열 값 기반의 메서드가 빈 세트을 반환해야 할 때 null 값 대신에 빈 배열을 반환하는 것을 선호합니다.
이러한 코딩 방식은 C#이나 Java와 같은 다수의 관리되는 언어에서는 흔한 일입니다.
일반적으로 메서드에서 길이가 0인 배열을 반환할 때, 매번 새로운 배열을 생성하는 것보다 미리 할당된 싱글톤 인스턴스로 반환하는 것이 더 효율적입니다.
물론, 배열이 반환된 후 크기 조절되는 경우에는 예외가 발생되어야 합니다
6. 문자열과 텍스트
문자열과 텍스트 취급 문제는 유니티 프로젝트에서 성능 문제를 주로 유발하는 원인 중 하나입니다.
C#에서 모든 문자열은 변하지 않습니다. 문자열을 조작하면 전체 문자열이 새로 할당됩니다.
이것은 상대적으로 비용이 비싸며, 반복적인 문자열 연결은 크기가 큰 문자열, 큰 데이터세트 또는 빠르게 반복하는 루프에서 수행될 때 성능 문제가 발생할 수 있습니다.
또한, N개의 문자열 연결은 N–1개의 중간 문자열을 할당해야 하므로, 연쇄적인 연결은 관리되는 메모리에 큰 부담을 줄 수 있습니다.
문자열이 빠르게 반복하는 루프나 매 프레임에서 연결되어야 할 경우 실제 연결 작업을 하기 위해 StringBuilder를 사용합니다.
또한 StringBuilder 인스턴스는 불필요한 메모리 할당을 좀더 최소화하기 위해 재사용될 수 있습니다.
Microsoft는 C# 에서 문자열 작업에 대한 베스트 프랙티스 리스트를 제공하고 있습니다.
MSDN 웹사이트인 msdn.microsoft.com를 참조하십시오.
6.1 로케일 강제 변환 및 서수 비교
문자열 관련 코드에서 종종 발견되는 중요한 성능 문제 중의 하나는 속도가 느린 기본 문자열 API를 의도치 않게 사용했을 때 발생합니다.
API는 업무용 애플리케이션용으로 만들어졌으며 텍스트에 있는 문자를 고려하여 여러가지 다른 문화적, 언어적 규칙으로 문자열을 다루려고 시도합니다.
예를 들어, 다음의 예제 코드는 미국식 영어 로케일에서 실행된 경우 true 를 리턴하지만, 다수의 유럽어 로케일에서는 false를 리턴합니다
Unity 버전 5.3과 5.4의 경우, 유니티의 스크립팅 런타임은 항상 미국식 영어(en-US) 로케일에서 실행된다는 사실을 기억하십시오.
String.Equals("encyclopedia", "encyclopædia");
대부분의 Unity 프로젝트에서 이런 방식은 전혀 필요하지 않습니다.
C나 C++ 프로그래머들이 친숙한 방식으로 문자열을 비교하는 서수 비교 방식을 사용하는 것이 대략 열 배는 빠릅니다.
이것은 바이트로 표현되는 문자를 고려하지 않고 문자열의 각 바이트를 단순히 순차 비교하는 방식입니다.
서수 문자열 비교 방식으로 바꾸는 것은 간단한데, String.Equals의 마지막 인수로 StringComparison.Ordinal를 작성하기만 하면 됩니다.
myString.Equals(otherString, StringComparison.Ordinal);
6.2 비효율적인 빌트인 문자열 API
서수 비교로 전환하는 것 외에, 특정 C# String API는 매우 비효율적인 것으로 알려져 있습니다.
그 중에는 String.Format, String.StartsWith, String.EndsWith. String.Format 등이 있습니다.
특히 String.Format은 대체하기 어렵지만, 비효율적인 문자열 비교 메서드를 간단하게 최적화됩니다.
Microsoft는 현지화를 위해 조정될 필요가 없는 모든 문자열 비교에 StringComparison.Ordinal을 전달하는 것을 추천하고 있지만, Unity 벤치마크에 의하면 사용자 구현 방식과 비교했을 때 이것의 영향은 상대적으로 아주 적은 것으로 나타납니다.
|
메서드 |
십만 개의 짧은 문자열 처리 시간(ms) |
|
String.StartsWith, 기본값 |
137 |
|
String.EndsWith, 기본값 |
542 |
|
String.StartsWith, 서수 |
115 |
|
String.EndsWith, 서수 |
34 |
|
커스텀 StartsWith으로 교체 |
4.5 |
|
커스텀 EndsWith으로 교체 |
4.5 |
String.StartsWith와 String.EndsWith 둘 다 다음의 예제와 같이, 간단하게 핸드 코딩한 것으로 교체할 수 있습니다.
public static bool CustomEndsWith(string a, string b)
{
int ap = a.Length - 1;
int bp = b.Length - 1;
while (ap >= 0 && bp >= 0 && a[ap] == b[bp])
{
ap--;
bp--;
}
return (bp < 0 && a.Length >= b.Length) ||
(ap < 0 && b.Length >= a.Length);
}
public static bool CustomStartsWith(string a, string b)
{
int aLen = a.Length;
int bLen = b.Length;
int ap = 0; int bp = 0;
while (ap < aLen && bp < bLen && a[ap] == b[bp])
{
ap++;
bp++;
}
return (bp == bLen && aLen >= bLen) ||
(ap == aLen && bLen >= aLen);
}
6.3 정규 표현식
정규 표현식은 문자열을 비교하고 조작할 수 있는 강력한 방법이지만, 성능을 극단적으로 요구할 수 있습니다.
또한, C# 라이브러리의 정규 표현식 구현 방식으로 인하여, 간단한 bool 값의 IsMatch 질의라도 “엔진 내부”에 큰 일시적인 데이터 구조를 할당합니다.
이러한 일시적인 관리되는 메모리의 변동은 초기화 중일 때를 제외하고는 적합하지 않는 것으로 간주합니다.
정규 표현식이 필요하다면, 정규 표현식을 문자열 파라미터로 받는 Regex.Match 나 Regex.Replace 등의 정적 메서드는 사용하지 않는 것을 강력히 권장합니다.
이 메서드는 정규 표현식을 바로바로 컴파일하며, 생성된 오브젝트를 캐시하지 않습니다.
이 예제는 무해해 보이는 한 줄 코드입니다.
Regex.Match(myString, "foo");
하지만, 이 코드가 실행될 때마다 5KB 정도의 가비지가 생성됩니다.
간단한 리펙토링으로 대부분의 가비지를 제거할 수 있습니다.
var myRegExp = new Regex("foo");
myRegExp.Match(myString);
이 예제에서, myRegExp.Match을 호출하면 “오직” 320바이트의 가비지만 생성됩니다.
물론 이는 간단한 매치 작업이라는 것을 감안할 때 여전히 비용이 많이 들지만 이전 예제보다 상당히 개선된 것입니다.
따라서 정규 표현식이 불변의 문자열 리터럴인 경우, 이를 Regex 오브젝트 생성자의 첫 파라미터로 전달하여 미리 컴파일하는 것이 상당히 효율적입니다.
그 다음 미리 컴파일된 Regex 오브젝트는 재사용되어야 합니다.
6.4 XML, JSON과 그 외 긴 형식의 텍스트 파싱
텍스트 파싱은 로딩 시간에 발생하는 가장 무거운 작업 중에 하나입니다.
몇몇 경우, 텍스트를 파싱하는 데 걸리는 시간이 에셋을 로드하고 인스턴스화하는 데 걸리는 시간보다 더 클 수 있습니다.
이는 주로 어떤 구문 분석을 사용하는가에 따라 달라집니다.
C# 빌트인 구문분석은 대단히 유연하지만, 결과적으로 특정 데이터 구조에 대해는 최적화할 수 없습니다.
많은 수의 서드 파티 구문 분석은 반사를 기반으로 빌드되어 있습니다.
물론 반사는 개발 중에는 탁월한 선택이지만(데이터 구조의 변경에도 구문 분석이 빠르게 이에 적응할 수 있기 때문), 느린 것으로 악명이 높습니다.
Unity는 빌트인 JSONUtility API로 부분적인 해결책을 도입했습니다.
이 API는 JSON을 읽고 작성하는 Unity 직렬화 시스템에 대한 인터페이스를 제공합니다.
대부분의 벤치 마크에서 순수한 C# JSON 구문 분석보다 빠르지만, 다른 Unity 직렬화 시스템에 대한 인터페이스와 동일한 제약을 가지고 있습니다.
즉 추가 코드 없이 Dictionary 같은 다수의 복잡한 데이터 형식을 직렬화할 수 없습니다.
Unity 직렬화 과정 중에 복잡한 데이터 형식을 양방향으로 전환하는 데 필요한 추가적인 과정을 쉽게 넣는 한가지 방법으로 ISerializationCallbackReceiver 인터페이스를 참조하십시오.
텍스트 데이터 구문 분석으로 인하여 성능 문제를 겪는 경우, 다음의 세 가지 대안을 고려하십시오.
6.4.1 방법 1: 빌드할 때 구문 분석
텍스트 구문 분석의 부하를 피하는 가장 좋은 방법은, 런타임 시점에 텍스트 구문 분석을 완전히 제거하는 방법입니다.
일반적으로 이는, 일종의 빌드 단계를 통해 텍스트 데이터를 바이너리 포맷으로 “베이킹”한다는 것을 의미합니다.
이러한 방법을 선택하는 대부분의 개발자들은 데이터를 ScriptableObject 파생 클래스 계층 구조 등으로 이동시킨 후, 에셋 번들을 통해 데이터를 배포합니다.
ScriptableObject의 사용에 관련된 훌륭한 강연이 있습니다.
YouTube에 있는 Richard Fine’s Unite 2016 talk를 참조하십시오.
이 방법은 최상의 성능을 보장하지만, 동적으로 생성되어야 할 필요가 없는 데이터에 적합합니다.
게임 디자인 파라미터나 기타 콘텐츠에 가장 적합합니다.
6.4.2 방법 2: 분할 및 지연 로드
두 번째 방법은 구문 분석되어야 하는 데이터를 작은 부분으로 분할하는 것입니다.
데이터를 분할하면 이를 구문 분석하는 데 필요한 비용이 다수의 프레임으로 분산됩니다.
이상적으로는 사용자에게 원하는 경험을 제공하기 위해 필요한 데이터의 특정 부분을 파악하고, 해당 데이터만 로드하는 것입니다.
간단한 예제를 들어보겠습니다.
만약 프로젝트가 플랫폼 게임인 경우 모든 레벨 데이터를 거대한 덩어리 하나로 직렬화할 필요는 없습니다.
각각의 레벨마다 개별 에셋으로 데이터를 분할하고, 레벨을 세그먼트 별로 세분화했다면, 플레이어가 레벨에 접근할 때 데이터를 구문 분석할 수 있게 됩니다.
이는 쉬워보이지만, 현실적으로는 툴 코드에 대한 상당한 투자를 필요로 하며, 데이터 구조를 재구성해야 할 수도 있습니다.
6.4.3 방법 3: 스레드
순수 C# 오브젝트에 전부 파싱되고, Unity API와 상호작용을 필요로 하지 않는 데이터의 경우, 해당 데이터의 파싱 작업을 워커 스레드가 담당하도록 할 수 있습니다.
이 방법은 멀티 코어를 가진 플랫폼에서 매우 강력합니다.
iOS 장치는 많아야 2개의 코어를, Android 디바이스는 24개를 가지고 있다는 점을 기억하십시오.
이 방법은 스탠드얼론 및 콘솔 빌드 타겟을 빌드할 때 적합합니다
하지만, 이 방법을 사용할 경우 데드록이나 레이스 조건을 방지하기 위해서는 조심스럽게 프로그래밍하여야 합니다.
스레딩을 도입하는 프로젝트는 일반적으로 워커 스레드를 관리하기 위한 목적으로 내장 C# 스레드 와 ThreadPool 클래스(msdn.microsoft.com를 참조하십시오)를 표준 C# 동기화 클래스와 더불어 사용합니다.
7. 리소스 폴더
Unity 프로젝트의 문제는 일반적으로 Resources 폴더에서 발생합니다.
Resources 폴더를 잘못 사용할 경우 프로젝트 빌드 크기가 커지고 통제 불가능할 정도로 과도한 메모리 사용이 발생되어, 애플리케이션 시작 시간이 크게 늘어날 수 있습니다.
위와 같은 문제는 베스트 프랙티스 가이드 에셋 번들과 리소스에 상세하게 설명돼 있습니다.
특히 리소스를 참조하시면 자세한 내용을 확인할 수 있습니다.
8. 일반 최적화
여러 가지 이유로 성능 문제가 발생하는 것처럼 코드 최적화도 다양한 방법으로 수행할 수 있습니다.
개발자들은 CPU 최적화를 적용하기 전에 항상 애플리케이션을 면밀히 검토해야 합니다.
하지만 보편적으로 적용 가능한 간단한 CPU 최적화도 있습니다.
8.1 ID별 주소 프로퍼티
Unity에서는 내부적으로 문자열 이름을 사용하여 애니메이터, 머티리얼 및 셰이더 프로퍼티를 지정하지 않습니다.
속도 개선을 위해 모든 프로퍼티 이름은 프로퍼티 ID로 해시되며, 이 ID가 실제로 프로퍼티를 지정하는 데 사용됩니다.
따라서 애니메이터, 머티리얼이나 셰이더에서 Set 이나 Get 메서드를 사용할 때는 항상 문자열 값 메서드 대신 정수값 메서드를 이용합니다.
문자열 방식은 간단히 문자열 해싱을 수행한 후 해시된 ID를 정수값 메서드로 전달합니다.
문자열 해시에서 생성된 프로퍼티 ID는 단일 실행 과정에서 결정적인 값을 가집니다.
프로퍼티 ID를 사용하는 가장 간단한 방법은 각 프로퍼티 이름마다 정수 변수를 선언하여 해당 스트링 자리에 정수 변수를 사용하는 것입니다.
이는 시작 시 자동으로 초기화되며 추가적인 초기화가 필요하지 않습니다.
애니메이터 프로퍼티 이름에 적합한 API는 Animator.StringToHash이고, 머티리얼 및 셰이더 프로퍼티 이름에 적합한 API는 Shader.PropertyToID입니다.
8.2 비할당 물리 API 사용
Unity 5.3 이상 버전에서 모든 물리 쿼리 API의 비할당 버전이 도입되었습니다.
RaycastAll 호출을 RaycastNonAlloc으로 대체하고, SphereCastAll 호출은 SphereCastNonAlloc으로 대체합니다.
2D 애플리케이션의 경우에도 모든 Physics 2D 쿼리 API의 비할당 버전이 제공됩니다.
8.3 UnityEngine.Object 서브 클래스에 대한 null 비교
Mono 및 IL2CPP 런타임은 UnityEngine.Object에서 파생되는 클래스의 인스턴스를 특정한 방식으로 처리합니다.
인스턴스에서 메서드를 호출하면 실제로는 엔진 코드로 호출되기 때문에 룩업 및 확인을 수행하여 스크립트 레퍼런스를 네이티브 레퍼런스로 전환해야 합니다.
크기는 작지만 이 유형의 변수를 null과 비교하는 것은 순수 C# 변수에 대해 비교하는 것보다 훨씬 더 많은 성능이 소모됩니다.
따라서 빠른 루프에서 또는 프레임마다 실행되는 코드에서는 null 비교를 가급적 사용하지 마십시오.
8.3.1 벡터와 쿼터니언 연산 및 연산 순서
빠르게 반복하는 루프에 위치한 벡터 및 쿼터니언 연산의 경우 부동 소수점보다 정수 연산의 속도가 빠르며, 부동 소수점 연산의 속도가 벡터, 매트릭스 또는 쿼터니언 연산보다 빠르다는 점을 기억하십시오.
따라서 가환 연산 또는 결합 연산이 허용될 경우 개별 수학 연산에 드는 성능 소모를 최소화할 수 있습니다.
Vector3 x;
int a, b;
// Less efficient: results in two vector multiplications
Vector3 slow = a * x * b;
// More efficient: one integer mult, one vector mult
Vector3 fast = a * b * x;
8.4 빌트인 ColorUtility
HTML 형식의 컬러 문자열(#RRGGBBAA)과 Unity의 네이티브 Color 및 Color32 구조체 간에 전환해야 하는 애플리케이션의 경우 Unify Community의 스크립트를 사용하는 것이 일반적입니다.
이 스크립트는 문자열 조작으로 인해 속도가 느리고 메모리 사용량이 컸습니다.
Unity 5에서는 이러한 전환을 효율적으로 수행하는 빌트인 ColorUtility API가 제공됩니다.
이 빌트인 API를 사용하는 것이 좋습니다.
8.5 Find 및 FindObjectOfType
출시 단계의 코드에서 Object.Find와 Object.FindObjectOfType의 사용을 모두 제거하는 것이 일반적으로 가장 좋습니다.
이러한 API는 Unity가 메모리에 있는 모든 게임 오브젝트와 컴포넌트에 대해 반복해서 수행하기 때문에 프로젝트의 범위가 커질수록 빠르게 성능이 저하됩니다.
싱글톤 오브젝트의 접근자에 대해 위의 법칙에 대한 예외를 만들 수 있습니다.
전역 관리자 오브젝트는 보통 “인스턴스” 프로퍼티를 노출하며, 기존에 존재하는 싱글톤 인스턴스를 감지하기 위해 보통 게터 안에 FindObjectOfType 호출이 있습니다.
class SomeSingleton
{
private SomeSingleton _instance;
public SomeSingleton Instance
{
get
{
if(_instance == null)
{
_instance = FindObjectOfType<SomeSingleton>();
}
if(_instnace == null)
{
_instance = CreateSomeSingleton();
}
return _instance;
}
}
}
이 패턴은 일반적으로 허용되지만, 싱글톤 오브젝트가 존재하지 않는 씬에서 이 접근자가 호출되는지 코드를 확인하는 것이 중요합니다.
게터가 누락된 싱글톤 인스턴스를 자동으로 생성하지 않을 경우 싱글톤을 찾는 코드가 FindObjectOfType을 반복적으로 프레임당 여러 번 호출하게 되어 바람직하지 않은 성능 저하가 자주 발생합니다.
8.5.1 카메라 로케이터
내부적으로 Camera.main 프로퍼티는 Object.FindObject의 특화된 배리언트인 Object.FindObjectWithTag를 호출합니다.
이 프로퍼티에 액세스하는 것은 Object.FindObjectOfType을 호출하는 것보다 비효율적입니다.
코드가 반드시 메인 카메라를 지정해야 하는 경우 다음 방법 중 하나를 수행하십시오.
- Start 또는 OnEnable 콜백에서 Camera.main에 액세스하고 그에 따른 레퍼런스 값을 저장합니다.
- 액티브 카메라에 레퍼런스 값을 제공하거나 삽입할 수 있는 Camera Manager 클래스를 구성합니다.
8.6 디버그 코드 및 [Conditional] 속성
UnityEngine.Debug 로깅 API는 개발 모드가 아닌 빌드에서도 제거되지 않으며, 호출될 경우 로그 파일에 기록합니다.
대부분의 개발자가 개발 모드가 아닌 빌드에는 디버그 정보를 기록하지 않으므로 다음과 같이 사용자 정의 메서드에 개발 모드 전용 로깅 호출로 래핑하는 것이 좋습니다.
public static class Logger
{
[Conditional("ENABLE_LOGS")]
public static void Debug(string logMsg)
{
UnityEngine.Debug.Log(logMsg);
}
}
이러한 메서드를 [Conditional] 속성으로 작성하면 Conditional 속성에서 사용되는 define에 따라 컴파일된 소스에 작성된 메서드가 포함되는지 여부를 결정합니다.
Conditional 속성에 전달된 define이 하나도 정의되지 않은 경우 작성된 메서드와 작성된 메서드의 모든 호출이 컴파일을 통해 제외됩니다.
이 효과는 해당 메서드와 그 메서드의 모든 호출이 #if … #endif 전처리기 블록에 둘러싸였을 때와 동일합니다.
Conditional 속성에 관한 더 자세한 내용은 MSDN 웹사이트를 참조하십시오. msdn.microsoft.com
9. 특별 최적화
이전 섹션에서는 모든 프로젝트에 적용 가능한 최적화에 대해 설명했지만, 이 섹션에서는 프로파일링 데이터를 모으기 전에 적용되지 말아야 할 최적화에 대해 자세하게 설명합니다.
최적화를 수행하는 것은 노동 집약적이며, 성능을 위해 코드의 말끔함 또는 유지보수의 용의성을 타협할 수 있으며, 또는 어느 정도 규모일 때만 나타나는 문제를 해결할 수도 있기 때문입니다.
9.1 다차원 배열 vs 가변 배열
StackOverflow 항목에 설명되어 있듯이, 다차원 배열은 함수 호출이 필수이기 때문에, 이를 반복하는 것보다는 가변 배열을 반복하는 것이 일반적으로 더 효율적입니다.
참고:
- 이것을 배열의 배열이며, type[x,y] 대신 type[x][y]로 명시됩니다.
- ILSpy 또는 유사 툴을 사용하여 다차원 배열에 액세스할 때 생성되는 IL를 검사하면 이를 파악할 수 있습니다.
Unity 5.3 버전에서 프로파일링 했을 때, 3차원의 100x100x100 배열을 100번 완벽히 연속 반복했을 경우 다음과 같은 시간이 소요되었으며, 이는 테스트를 10번 이상 수행해서 평균을 계산했습니다.
| 배열 | 종류전체 시간 (100회 반복) |
|
일차원 배열 |
660ms |
|
가변 배열 |
730ms |
|
다차원 배열 |
3,470ms |
추가 함수 호출 비용은 다차원 배열 vs 일차원 배열을 액세스 하는 비용 차이에서 확인할 수 있으며, 간결하지 않은 메모리 구조를 반복하는 비용은 가변 배열 vs 일차원 배열의 비용 차이에서 확인할 수 있습니다.
위에서 설명했듯이, 추가 함수 호출 비용은 간결하지 않은 메모리 구조를 사용하여 든 비용보다 훨씬 더 많이 듭니다.
성능에 특히 민감한 작업의 경우, 일차원 배열 사용을 권장합니다.
이 외에 다차원의 배열이 필요한 모든 경우에는, 가변 배열을 사용하시기 바랍니다.
다차원 배열을 사용해선 안 됩니다.
9.2 파티클 시스템(Particle System) 풀링
파티클 시스템 풀링에는 최소 3,500바이트 이상의 메모리가 소모된다는 것을 유의하시기 바랍니다.
메모리 소모는 파티클 시스템에 활성화 된 모듈의 수에 따라 늘어납니다.
이 메모리는 파티클 시스템이 비활성화된 경우에는 해제되지 않습니다.
파티클 시스템이 파괴됐을 경우에만 해제됩니다.
Unity 5.3일 경우에, 대부분의 파티클 시스템 설정은 이제 런타임 시 조정할 수 있습니다.
여러 가지 다양한 파티클 효과를 풀링해야 하는 프로젝트의 경우, 파티클 시스템의 설정 파라미터를 데이터 저장 클래스나 구조체로 추출하는 것이 더 효율적일 수 있습니다.
파티클 효과가 필요할 경우, “일반” 파티클 효과 풀에서 필요한 파티클 효과 오브젝트를 공급할 수 있습니다.
그 다음 설정 데이터를 오브젝트에 적용하여 원하는 그래픽 효과를 얻을 수 있습니다.
이것은 주어진 씬에서 사용되는 파티클 시스템의 가능한 모든 배리언트와 설정을 풀링하는 것보다 훨씬 더 메모리 효율적이지만 상당한 엔지니어링 노력이 필요합니다.
9.3 업데이트 관리자
내부적으로 Unity는 Update, FixedUpdate, LateUpdate 같은 콜백 함수와 관계 있는 오브젝트 리스트를 추적합니다.
리스트 업데이트가 계속 이뤄지도록 하기 위해 이 리스트는 intrusively-linked 리스트로 남아 있습니다.
MonoBehaviours는 활성화 되었을 경우 리스트에 추가되고, 비활성화 되었을 경우 리스트에서 삭제됩니다.
콜백이 필요한 MonoBehaviour에 적절한 콜백 함수를 손쉽게 추가할 수 있어 편리하지만 콜백 수가 늘어나면 비효율적입니다.
네이티브 코드에서 관리되는 코드 콜백을 호출하는 데에는 적지만 매우 중요한 오버헤드가 발생합니다.
이로 인해 대량의 프레임당 메서드를 호출할 때 프레임 시간이 저하되고 다수의 MonoBehaviour를 포함하는 프리팹을 인스턴스화할 때 인스턴싱 시간이 저하됩니다.
인스턴스화 비용은 프리팹의 각 컴포넌트에 Awake 및 OnEnable 콜백을 호츨하는 성능 오버헤드로 인해 발생합니다.
프레임당 콜백이 있는 MonoBehavious의 수가 수백 또는 수천으로 증가할 경우, 이러한 콜백을 제거하고 MonoBehaviour (또는 스탠다드 C# 오브젝트도)를 글로벌 관리자 싱글톤에 연결하는 것이 유리합니다.
글로벌 관리 싱글톤은 Update, LateUpdate 및 기타 콜백을 관련 오브젝트에 보낼 수 있습니다.
이 경우 오브젝트들이 별다른 동작이 없을 때 코드가 콜백 받는 것을 스마트하게 해제하고, 이것으로 프레임당 호출돼야 하는 함수의 전체 수가 감소하는 추가적인 이득이 있습니다.
절약을 가장 많이 할 수 있는 방법은 보통 거의 실행하지 않는 콜백을 제거하는 것입니다.
다음과 같은 의사 코드를 고려하십시오.
void Update() {
if(!someVeryRareCondition) { return; }
// … some operation …
}
위와 유사한 업데이트 콜백이 포함된 다수의 MonoBehaviour가 있을 경우 업데이트 콜백을 실행하는데 소요되는 시간 중 상당 부분이 즉시 종료되는 MonoBehaviour 실행을 위해 네이티브 코드 및 관리되는 코드 도메인을 전환하는 데에 사용됩니다.
someVeryRareCondition가 true일 때에만 이러한 클래스가 글로벌 업데이트 매니저에 등록하고 이후 해제할 경우 코드 도메인 전환 및 희귀한 조건 평가에 소요되는 시간을 절약할 수 있습니다.
9.3.1 업데이트 관리자에서 C# 델리게이트 사용
이러한 콜백을 실행하기 위해 플레인 C# 델리게이트를 사용하고자 할 수 있습니다.
하지만 C# 델리게이트 구현은 낮은 비율의 구독과 구독 취소 및 적은 수의 콜백에 최적화되어 있습니다.
C# 델리게이트는 한 번 콜백이 추가 또는 제거될 때마다 해당 콜백 리스트 전체를 깊게 복사 합니다.
콜백 리스트가 많거나, 하나의 프레임당 콜백의 구독/구독 취소하는 수가 많을 경우 내부 Delegate.Combine 메서드의 성능이 순간적으로 크게 나빠집니다.
추가/제거가 빈번히 일어날 경우, 델리게이트 대신 빠른 삽입/제거를 위해 만들어진 데이터 구조를 사용하는 것을 고려해 보십시오.
9.4 스레드 컨트롤 로딩
Unity는 개발자가 데이터를 로드하기 위해 사용되는 배경 스레드의 우선 순위를 조정하는 것을 허용합니다.
이는 에셋 번들을 배경의 디스크에 스트리밍할 때 특히 중요합니다.
메인 스레드와 그래픽스 스레드의 우선 순위는 ThreadPriority.Normal입니다.
더 높은 우선 순위를 가지는 스레드는 메인/그래픽 스레드를 선점하며 프레임 속도의 끊김 현상을 발생시키는 반면, 우선 순위가 낮은 스레드는 그렇지 않습니다.
여러 스레드가 메인 스레드와 우선 순위가 동일할 경우 CPU는 모든 스레드에 동일한 시간을 주려고 합니다.
그 결과 여러 배경 스레드가 에셋 번들 압축 풀기 등과 같이 용량이 큰 작업을 수행할 경우 일반적으로 프레임 속도가 느려지는 현상이 발생합니다.
현재 세 곳에서 우선 순위를 조정할 수 있습니다.
첫째, Resources.LoadAsync나 AssetBundle.LoadAssetAsync와 같은 에셋 로딩 호출의 디폴트 우선 순위는 Application.backgroundLoadingPriority 설정에서 정할 수 있습니다.
앞서 설명했듯이, 이 호출은 메인 스레드가 에셋을 통합하는 데 사용하는 시간 양도 제한합니다
대부분의 Unity 에셋 타입은 메인 스레드로 “통합”돼야 합니다.
통합 과정에서 에셋 초기화가 완료되며 특정 스레드 세이프 작업이 수행됩니다.
작업에는 Awake 콜백 등과 같은 스크립팅 콜백 호출이 포함됩니다.
에셋 로딩이 프레임 타임에 미치는 영향을 제한하는 방법에 대한 자세한 내용은 “자원 관리(Resource Management)” 가이드를 참조하십시오.
둘째, 각각의 UnityWebRequest 요청과 마찬가지로 각각의 비동기 에셋 로딩 작업은 AsyncOperation 대상을 반환하여 작업을 모니터 및 관리하도록 합니다.
AsyncOperation 대상은 개별 작업의 우선 순위를 수정하는 데 사용할 수 있는 우선순위 프로퍼티를 제공합니다.
마지막으로, WWW.LoadFromCacheOrDownload의 호출에서 반환된 WWW 객체는 threadPriority 프로퍼티를 제공합니다.
WWW 객체은 기본값으로 Application.backgroundLoadingPriority 설정을 자동으로 사용하지는 않습니다 – WWW 객체는 항상 기본값이 ThreadPriority.Normal입니다.
데이터 압축 해제 및 로드하는 데 사용되는 엔진 내부 시스템은 API마다 다르다는 점을 유의하십시오. Resources.LoadAsync와 AssetBundle.LoadAssetAsync는 로딩 스레드를 담당하고 자체 속도 제한을 수행하는 Unity의 내부 PreloadManager 시스템에서 작동됩니다.
UnityWebRequest는 전용 스레드 풀을 사용합니다.
요청이 생성될 때마다 WWW는 완전히 새로운 스레드를 생성합니다.
다른 모든 로딩 메커니즘은 대기열 시스템이 내장되어 있는 반면 WWW는 그렇지 않습니다.
매우 많은 수의 압축 에셋 번들에서 WWW.LoadFromCacheOrDownload를 호출할 경우 동일한 수의 스레드가 생성되며, 이 스레드는 CPU 시간에 대해 메인 스레드와 경쟁합니다.
그 결과 프레임 속도가 끊어지는 현상이 쉽게 발생할 수 있습니다.
따라서 WWW를 사용하여 에셋 번들을 로드하고 압축 해제할 때, 생성되는 각각의 WWW 오브젝트의 threadPriority에 해당하는 적절한 값을 설정하는 것이 가장 좋습니다.
9.5 매스 오브젝트 이동 & CullingGroups
트랜스폼 조작에 대한 섹션에서 언급했듯이 큰 트랜스폼 계층 구조를 이동할 경우 변경 메시지 증가로 인해 CPU 사용량이 상대적으로 많이 듭니다.
하지만 실제 개발 환경에서는 계층 구조를 적당한 수의 게임 오브젝트로 떨어뜨리는 것이 불가능한 경우가 있습니다.
동시에 사용자가 눈치채지 못할 동작을 제거하면서 게임 월드에 대한 신뢰성을 유지할 수 있을 정도의 동작만 실행하는 것은 좋은 개발 방향입니다.
예를 들어, 캐릭터 수가 많은 씬에서 화면 위에 있는 캐릭터의 메시 스키닝과 애니메이션 중심의 트랜스폼 이동만 실행하는 것이 더 최적입니다.
스크린 밖의 캐릭터 시뮬레이션의 시각적 요소를 계산하는 데 CPU 시간을 낭비할 이유가 없습니다.
Unity 5.1에서 처음 소개된 API로 이런 문제를 깔끔하게 해결할 수 있습니다. CullingGroups.
씬에 있는 여러 그룹의 게임 오브젝트를 직접 조작하는 대신 CullingGroup에 있는 한 BoundingSphere 그룹의 Vector3 파라미터를 조작하도록 시스템을 변경합니다.
각각의 BoundingSphere는 단일 게임 로지컬 엔티티의 월드 공간 포지션에 대한 신뢰할 만한 저장소 역할을 하고, 엔티티가 CullingGroup 메인 카메라의 절두체 내부 또는 근처로 이동할 때 콜백을 받습니다.
이 콜백은 엔티티가 보일 때만 실행해야 하는 동작을 관리하는 코드 또는 컴포넌트(Animator 등)를 활성화/비활성화하는 데 사용됩니다.
9.6 메서드 호출 오버헤드 감소
C#의 문자열 라이브러리는 추가적인 메서드 호출을 단순 라이브러리 코드에 추가하는 비용에 대해 훌륭한 연구 사례를 제공합니다.
빌트인 문자열 API String.StartsWith과 String.EndsWith에 관한 섹션에서는, 원치 않는 로케일이 강제 억제돼도 직접 코딩한 대체 코드가 빌트인 메서드보다 10100배 빠르다고 언급되어 있습니다.
이렇게 성능 차이가 발생하는 가장 큰 이유는 부가적인 메서드 호출을 빠르게 반복하는 내부 루프에 추가하는 비용 때문입니다.
호출된 각각의 메서드는 메서드의 주소를 메모리에 저장하고 다른 프레임을 스택에 푸시해야 합니다.
이러한 작업은 비용이 없지않지만 대부분의 코드에서 무시할 정도로 충분히 작습니다.
하지만 빠르게 반복하는 루프에서 작은 메서드를 실행할 때 부가적인 메서드 호출을 도입하면서 추가된 오버헤드는 중요하며 심지어 우세할 수 있습니다.
다음의 두 가지 단순 메서드를 고려하십시오.
예제1:
int Accum { get; set; }
Accum = 0;
for(int i = 0; i < myList.Count; i++) {
Accum += myList[i];
}
예제2:
int accum = 0;
int len = myList.Count;
for(int i = 0; i < len; i++) {
accum += myList[i];
}
두 메서드 모두 C# 일반 List<int>에 있는 모든 정수의 총합을 계산합니다.
첫 번째 예제는 데이터 값을 보유하기 위해 자동으로 생성된 프로퍼티를 사용한다는 점에서 좀더 “현대적인 C#” 입니다.
겉으로는 두 개의 코드가 동일해 보이지만, 메서드 호출에 대해 코드를 분석할 경우 차이가 극명합니다.
예제1:
int Accum { get; set; }
Accum = 0;
for(int i = 0;
i < myList.Count; // call to List::getCount
i++) {
Accum // call to set_Accum
+= // call to get_Accum
myList[i]; // call to List::get_Value
}
여기서, 루프를 실행할 때마다 메서드 호출이 네 번 있습니다.
- myList.Count는 Count 프로퍼티에 있는 대해 get 메서드를 호출합니다.
- Accum 프로퍼티에 있는 get과 set 메서드를 호출해야 합니다.
- 더하기 연산에 전달될 수 있도록 Accum의 현재 값을 가져오기 위해 get 합니다.
- 더하기 연산 결과를 Accum에 할당하기 위해 set 합니다.
- [] 연산자는 이 리스트의 특정 인덱스에 있는 값을 가져오기 위해 리스트의 get_Value 메서드를 호출합니다.
예제2:
int accum = 0;
int len = myList.Count;
for(int i = 0;
i < len;
i++) {
accum += myList[i]; // call to List::get_Value
}
두 번째 예제에서, get_Value 호출은 남아 있지만 그 밖의 다른 메서드는 모드 제거됐거나, 더 이상 루프를 반복할 때마다 실행되지 않습니다.
- accum이 이제 프로퍼티가 아닌 기본형 값이기 때문에, 값을 설정하거나 가져오기 위해 메서드를 호출할 필요가 없습니다.
- 루프가 실행되는 동안 myList.Count는 달라지지 않을 것으로 예상되기 때문에, 해당 루프의 조건문 밖으로 액세스를 이동되어 각 루프 반복이 시작될 때마다 더 이상 실행되지 않습니다.
두 가지 버전의 소요 시간은 특정 코드의 메서드 호출 오버헤드를 75% 제거하는 것의 진정한 이점을 보여줍니다.
최신 데스크톱 컴퓨터에서 100,000번 실행했을 때,
- 예제 1은 실행에 324ms 걸립니다.
- 예제 2는 실행에 128ms 걸립니다.
여기서 중요한 문제는 Unity가 거의 메서드를 인라이닝하지 않는다는 것입니다.
IL2CPP 하에서 조차도, 많은 메서드가 현재 적절히 인라인화 하지 못합니다.
특히 프로퍼티일 경우 더욱 그렇습니다.
또한, 가상 또는 인터페이스 메서드는 절대 인라인화 될 수 없습니다.
따라서 C# 소스에서 선언된 메서드 호출은 최종 바이너리 애플리케이션에서 결국 메서드 호출을 생산하게 될 가능성이 매우 높습니다.
9.6.1 단순 프로퍼티
Unity는 개발자들의 편의를 위해 데이터 형식에 많은 “단순한” 상수를 제공합니다.
하지만 위의 관점에서, 이런 상수는 일반적으로 상수값을 반환하는 프로퍼티로 구현됩니다.
Vector3.zero의 프로퍼티 실제 코드는 다음과 같습니다.
get { return new Vector3(0,0,0); }
Quaternion.identity도 매우 유사합니다.
get { return new Quaternion(0,0,0,1); }
이러한 프로퍼티에 액세스하는 비용은 프로퍼티 주변의 실제 코드와 비교했을 때는 보통 작은 수준이지만, 프레임당 수천 번(또는 그 이상) 실행될 경우에는 작은 차이가 발생할 수 있습니다.
단순한 기본형의 경우, const 값을 대신 사용합니다.
const 값은 컴파일할 때 인라인화 됩니다 - const 변수에 대한 참조는 이 값으로 대체됩니다.
const 변수의 모든 참조는 이 값으로 대체되기 때문에 긴 스트링이나 그 밖의 다른 데이터 타입 const를 선언하는 것은 권장하지 않습니다.
이는 최종 명령 코드에서 모든 복제 데이터로 인해 최종 바이너리의 크기가 불필요하게 부풀려지게 됩니다.
const가 적절하지 않은 곳에서는 static readonly 변수를 대신 사용합니다.
일부 프로젝트의 경우 Unity의 내장된 단순 프로퍼티조차 static readonly으로 대체되어 성능이 조금 개선됩니다.
9.6.2 단순 메서드
단순 메서드는 더 까다롭습니다.
특히 함수를 선언할 수 있고 어느 곳에서든 재사용하는데 매우 유용합니다.
하지만 빠르게 반복하는 내부 루프에서는 좋은 코딩 방식으로부터 벗어나 특정 코드를 “수동으로 인라인화”해야 할 수도 있습니다.
일부 메서드는 즉시 제거될 수 있습니다.
Quaternion.Set, Transform.Translate 또는 Vector3.Scale를 고려하십시오.
이러한 메서드는 매우 사소한 작업이기 때문에 간단한 대입문으로 대체될 수 있습니다.
더 복잡한 메서드의 경우, 성능이 좋은 코드를 유지하는 데 드는 장기적 비용에 대비해 수동 인라이닝에 대한 프로파일링 내용을 잘 비교해보십시오.
'유니티 > 최적화' 카테고리의 다른 글
| [유니티 최적화] 셰이더 작성 시 성능 팁 (0) | 2021.02.05 |
|---|---|
| [유니티 최적화] 최적의 성능을 위한 캐릭터 모델링 (0) | 2021.02.05 |
| [유니티 최적화] 반사 프로브 성능 및 최적화 (0) | 2021.02.05 |
| [유니티 최적화] 그래픽스 퍼포먼스 최적화 (2) | 2021.02.02 |
| [유니티 최적화] 유니티 최적화 (0) | 2020.02.26 |



